
併發程式的核心 - Atomic 不是鎖,那 Atomic 是什麼?
CPU MESI 以及 Memory Ordering 解析

atomic 是併發程式基礎,例如 mutex 底層是用 atomic Compare And Swap 實現的,然而在我深入研究錢,對 atomic 認知是 CPU 層級鎖,研究發現,atomic 是用來解決多核併發讀寫資料情況下,不同 cpu core 之間同步記憶體資料的機制。
現代 CPU 架構為何?如何跟 RAM 交互?
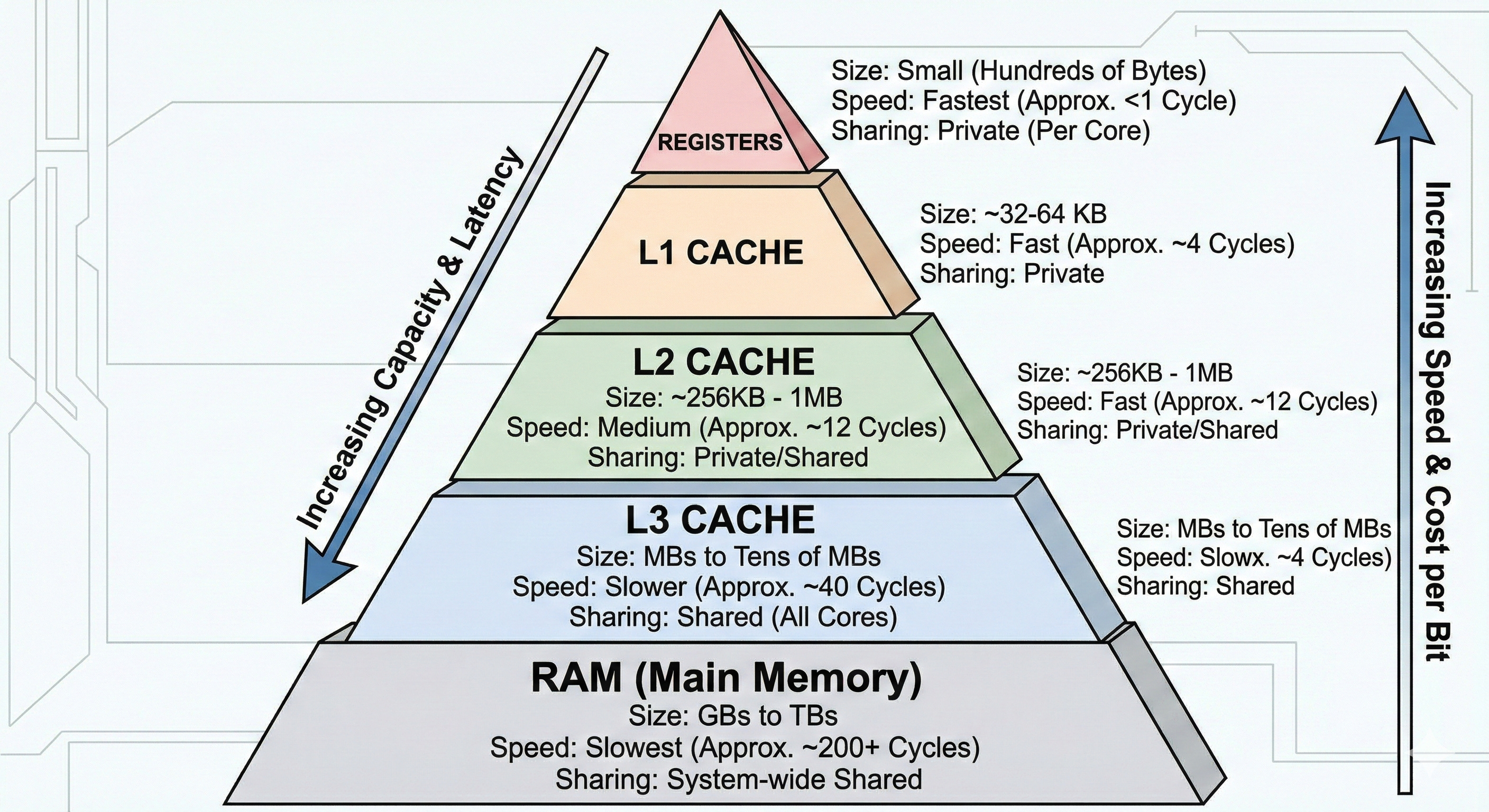
由於受限硬體電路的物理限制,記憶體容量越大,CPU 存取延遲越高,因此 CPU 採用多層記憶體階層(memory hierarchy)來降低平均存取成本。
每個 core 執行時會用 register 儲存運算時用的資料,為避免每執行到一個變數就存取一次記憶體,core 已 cache line (64B) 為單位從記憶體讀資料。
讀 cache line 不會整坨放到 register 中,而是放在不同層級的 cache,例如 L1, L2, L3 跟 RAM:
L1 是每個 core 私有
L2 多數也是 per-core 私有,部分架構可共享
L3 是多 core 共享的最後一層快取
RAM 最終的主記憶體存儲
大小是 RAM > L3 > L2 > L1 > register ,存取速度則相反。
core 查資料時,會從 L1 開始查,miss 後找 L2 -> L3 -> RAM,找到資料後會一路回填,放到 L3 -> L2 -> L1,回填時記憶體不夠就會 evict 其他 cache line 。
多層記憶體架構會有什麼問題?
當每個 core 執行 x++ 實際指令是:
LOAD x → register
ADD 1
STORE register → x若每次 STORE 都寫回 RAM,core 執行速度會變慢,因此 CPU 設計會將結果儲存在另一個硬體元件,store buffer,相當於每個 core 各自的 queue,交由 cache subsystem 將更新提交到 L1 cache line 並標記為 dirty,當 cache line eviction 或者收到 coherence write back 事件時寫回更低層快取或 RAM。
類似最終一致性,先提交到 L1,但 L1 不是共享的,要等 L1 滿了該 cache line 被 evict 才會逐步寫回 RAM,最終讓其他 core 讀到更新後資料。
因此當兩個 thread 在不同 core 執行 for loop { x++ } ,不同 core 將資料放到各自的 L1 cache,載入 register 運算,執行完在寫回 L1 cache,彼此之間有著相同 cache line 的不同副本,用各自副本反覆執行 ++ ,最終結果會 race condition。
CPU 多核架構如何解決 cache line 資料不同步的問題?
要解決不同步問題,首先要建立高效的同步管道,多 core 之間在硬體設計上會有 coherence interconnect 通道交換 cache line 資訊。
該通道主要不是用來交換更新後的 cache line 內容,因為併發寫入的情境中,我們需要確保寫入順序,跟寫入後要立刻同步才不會 race condition。
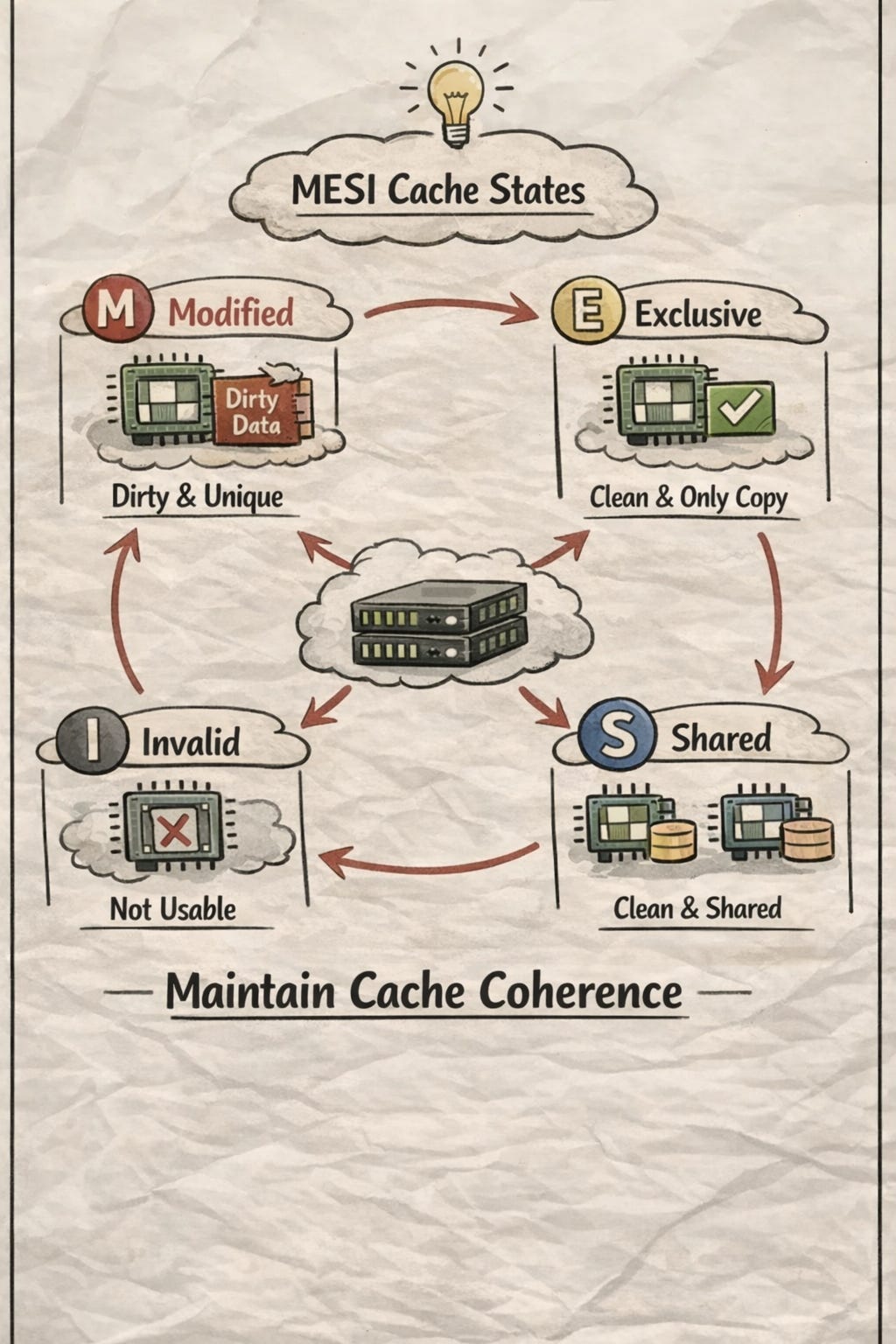
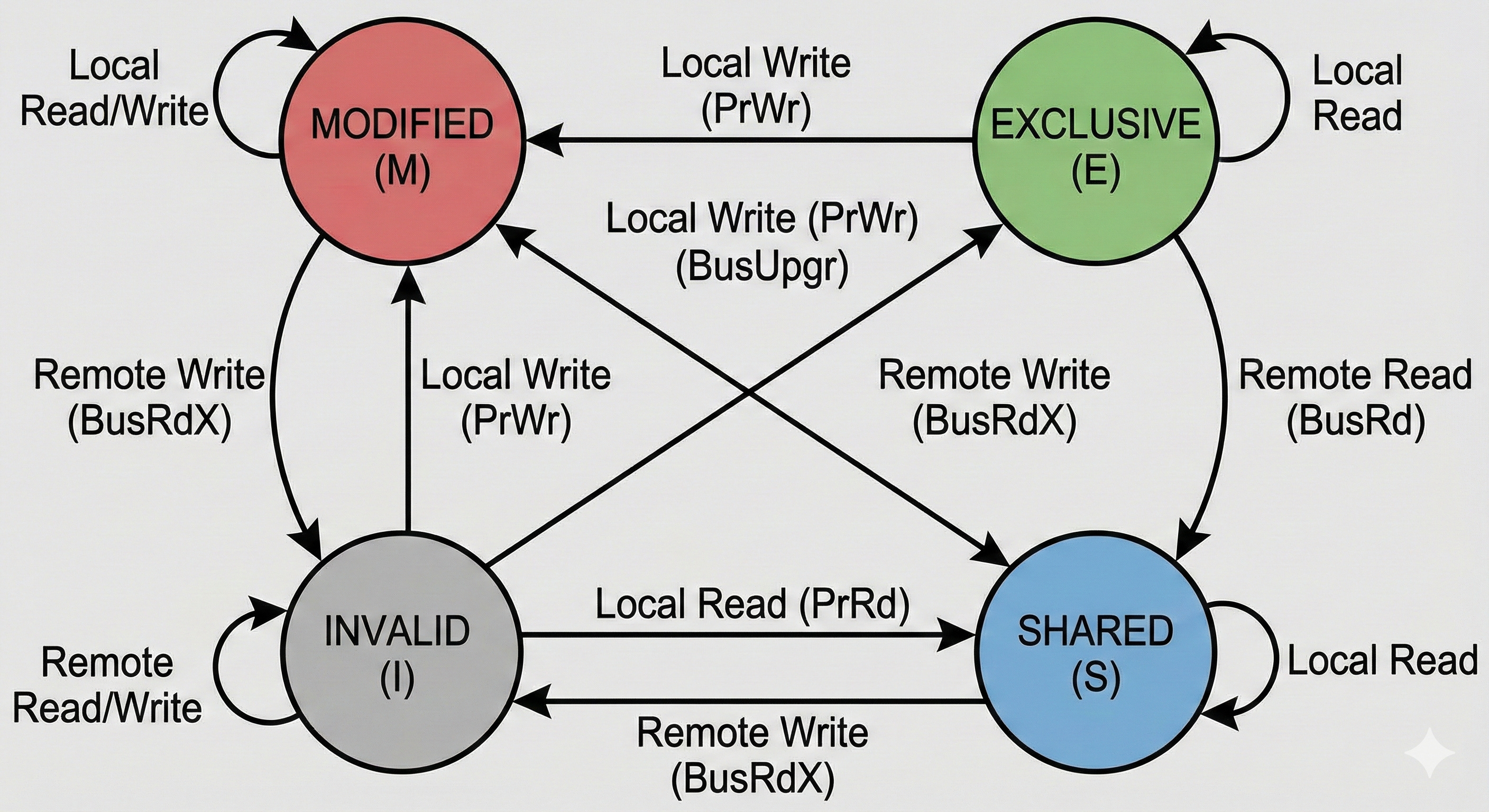
因此該通道主要是交換 cache line 的狀態,並用狀態表達 cache line 的 ownership,該狀態機制稱為 MESI(Modified, Exclusive, Shared, Invalid):
M : 該 cache line 被本 core 修改,但尚未寫回更低層 cache 或 RAM
E : 該 cache line 僅存在於本 core,內容與 RAM 一致,尚未被修改
S : 該 cache line 可能存在多個 core,內容與 RAM 一致,尚未被修改
I : 該 cache line 被其他 core 修改,不可使用,使用前透過 coherence interconnect 跟其他 core 拿或者去 L3 or RAM 拿
MESI 是 cache line 的狀態機,定義了 cache line 狀態的切換:
從「無」到「有」(I → E 或 I → S): core 讀取 cache line 最新狀態
從「讀」到「寫」(S → M) : core 獲取該 cache line ownership 並更新
從「有」到「無」( M → I) : core 收到別人修改該 cache line 通知,修改狀態成 I
從「髒」到「淨」( M → S) : core 收到別人讀該 cache line 通知,發現狀態沒同步到 L3 or RAM,立馬同步並把狀態變成 S,不會等 evict 才同步資料
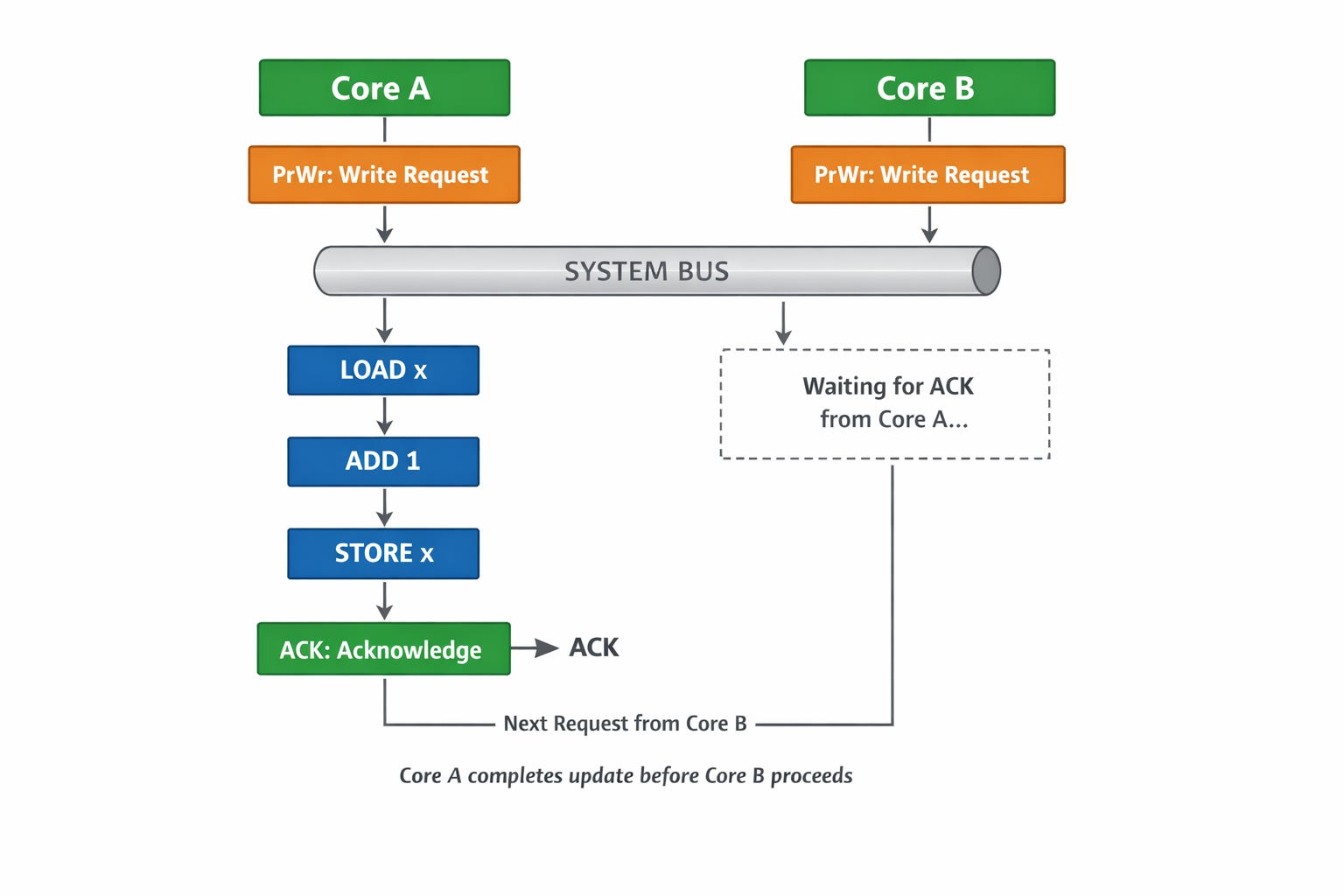
為確保同一時間同個 cache line 只有一個 core 獲得寫入 ownership,coherence interconnect 通道會是一個 BUS,多個 core 的寫入請求 (PrWr) 會被 BUS sequential 的執行,多個 core 會監聽 (snooping) BUS 的請求,收到回 ACK,BUS 收到所有 core 的 ACK 才處理下個請求。
例如 core A & core B 同時對 BUS 發請 cache line X 的 PrWr,BUS 先處理 core A 的 PrWr,:
當 core B 收到 core A 的 PrWr 會把自己的 cache line X 狀態改成 I,而 core A 收到大家的 ACK 會把狀態改成 M
隨後 BUS 在送出 core B 的 PrWr 時,core B 的狀態是 I 沒辦法改成 M,只能 NACK,然後改送 PrRd
當 core A 完成更新,收到 core B 的 PrRd,發現狀態是 M,將資料寫回 L3 or RAM,此時 core B 在去讀就能拿到最新的資料
最後 core B 再送一次 PrWr 拿到 ownership 後執行更新
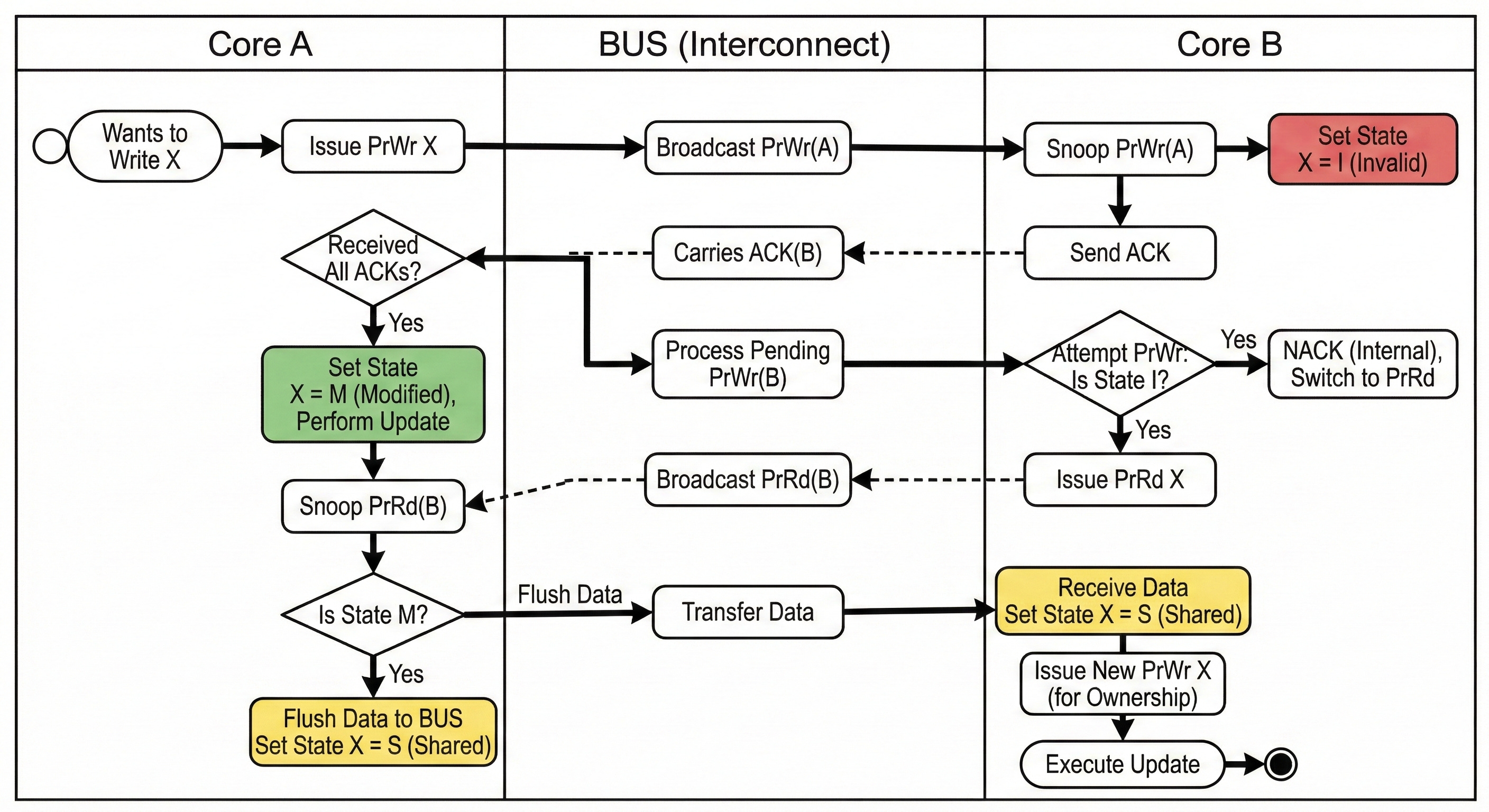
簡單來說,MESI 定義了 cache line 狀態機,中心化 BUS 確認狀態切換順序,多 core 透過 snooping 跟 ACK 機制確保同一時間點,大家對 cache line 狀態是一致的,不會同時兩個 core 對同個 cache line 都是M。
note: 現代 CPU 架構在 coherence interconnect 通道設計會優化效能,例如用 ring bus 或 mesh interconnect,配合 snoop filter 或 directory-based protocol。
但這樣就能解決 loop { x++ } 的問題嗎?
x++ 指令是:
LOAD x → register
ADD 1
STORE register → x是兩個狀態切換,LOAD 將 I => S,此時 CPU 將 x 放到 register,然後 ADD 1,執行 STORE 從 S => M 將資料寫回 L1 等別人要讀時寫回 L3 or RAM。
而同時 LOAD 是合法的,當 core A & core B 同時把 x 放到 register,core A 先執行 STORE 把 +1 後結果寫回,core B 要執行 STORE 時,雖然會等 core A 執行完,但是會用 register 中 core A STORE 前的值 ADD 1 ,最終仍會 race condition。
簡單來說 invalid 不處理 register 資料內容,register 一但放入就確定了,為解決該問題,atomic 可將 x++ 變成特殊指令 LOCK XADD,會把讀寫操作變成一個狀態切換確保其原子性。
例如兩個 core 同時執行 loop { atomic.add(&x, 1) },core A & core B 會同時發出 PrWr 請求,當 core A 先執行,他會一次完成 LOAD => ADD => STORE,三步驟完成後才回應下個請求的 ACK,這樣可確保該 cache line 下個狀態切換時,core A 已同步更新後資料給大家,避免了 core A & core B 同時 LOAD x 到 register 的可能。
該原子操作除了 x++ or x-- 還可用在 CAS (compare and swap) :
LOAD flag -> register
if flag == 0
flag = 1
STORE register -> flag
STORE true -> ok
else
STORE false -> okCAS 是 mutex 的核心,例如
lock => for (atomic.CAS(&lock, 0, 1))
unlock => (atomic.CAS(&lock, 1, 0))竟然 atomic 主要解決多步驟的原子性問題,那麼像 go 的 atomic.Store 跟 atomic.Load 只有單步驟為何需要 atomic?
MESI 實現狀態一致,但 ACK 機制會影響效能,主要有兩個延遲:
寫入延遲:當 core A 想寫資料 PrWr 時,必須等所有核心都回傳 ACK(確認已失效)才能真的更新,這段時間 core 只能停下來(stall)。
失效延遲:當 core B 收到 core A 的 PrWr 時,它必須將 L1 中 cache line 標記為 I 後才回傳 ACK,快取雖快,但處理速度仍比 register 慢得多,若 cache 正在忙,core A 就要等更久。
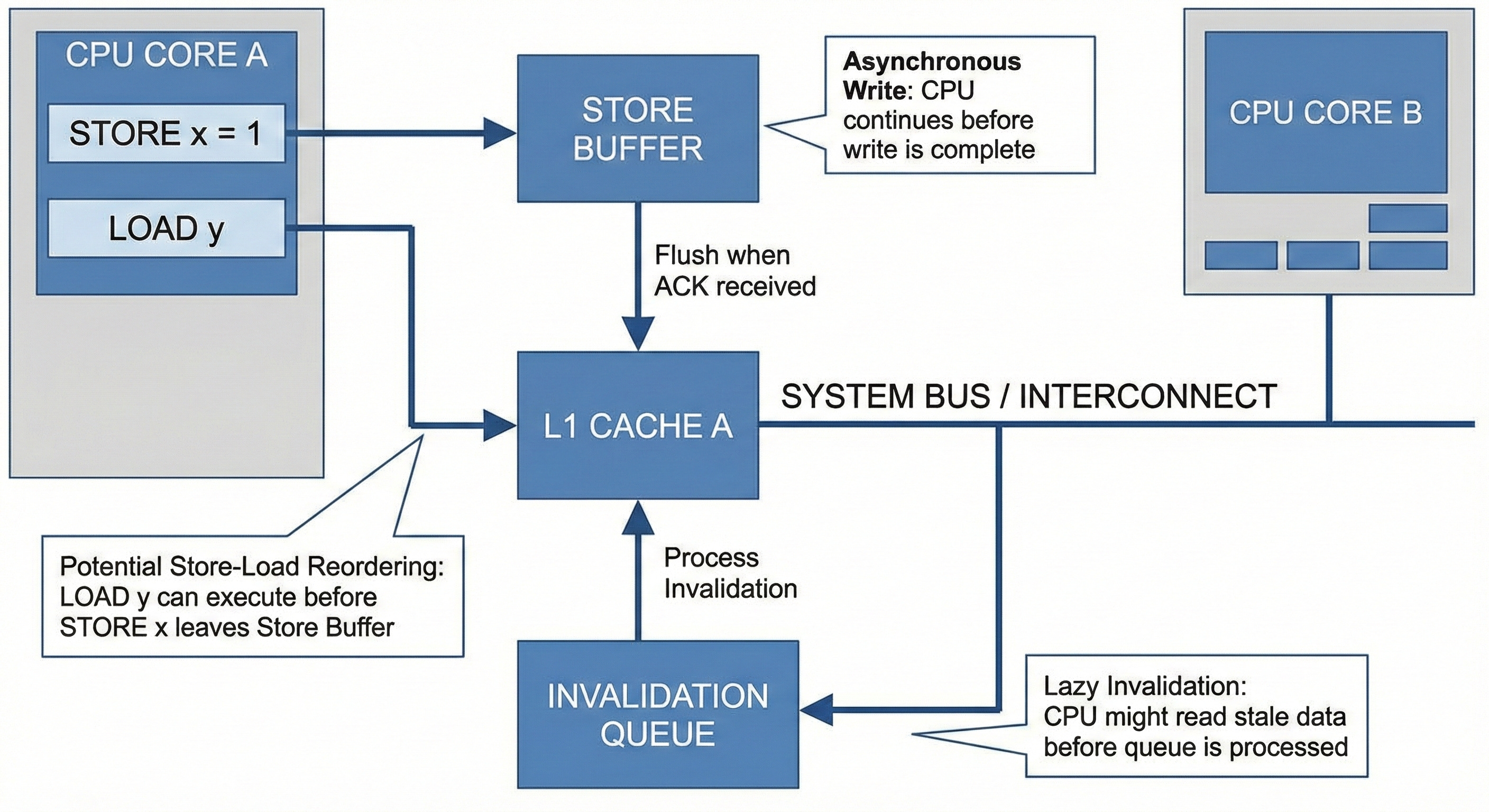
為優化效能,cpu 使用延遲執行優化:
解決寫入延遲,core 不會 stall 而是將要等 ack 的指令放到 store buffer 後往下一個指令處理,例如 :
a = 1;
b = y;
STORE 1 => a
LOAD y => register
STORE register => bSTORE 1 要等 ACK,先放到 store buffer 往下執行 LOAD y,如果 y 的 cache line 狀態是 E or S 就可直接放到 register,然後再回去執行 STORE 1 => a 跟 STORE register => b。
解決失效延遲,core 收到別人的 PrWr 不會馬上去記憶體標記 I,而是放到 invalidation queue 就回 ACK。
而上述兩個優化會影響資料讀寫的順序失靈,例如:
x = 0, y = 0, x_res =0, y_res = 0
core A
x = 1
if y == 0 {
x_res = 1
}
core B
y = 1
if x == 0 {
y_res = 1
}正常執行順序下:
core A 寫成功
core A 查詢 y == 0,寫 x_res
core B 寫成功
core B 檢查 x != 0
或者 core B 先寫成功,又或者 core 1 & core 2 都先寫成功:
core A 寫成功
core B 寫成功
core A 檢查 y != 0
core B 檢查 x != 0
總而言之,不可能同時出現 x_res 跟 y_res 同時為 1 的情況。
但如果 core A & core B 為優化寫入延遲,將 load y & load x 提前執行,就可能出現 x_res & y_res 同時為 1 的情況,也就是俗稱的 Store-Load Reorder 問題。
go 的 atomic.Store 跟 atomic.Load 如何解決 Store-Load Reorder 問題?
go 的 atomic.Store 本質是在 Store 後設置一個 barrier,強制 core 清空 store buffer,例如 :
atomic.Store(&x, 1)
b = y;雖然 STORE 1 => x 被放到 store buffer,但在執行 LOAD y 前會強制清空 store buffer 也就是等 STORE 1 收到 ACK 並完成更新,確保 STORE 1 => x 先被執行。
但只有 atomic.Store 仍不能解決下面問題:
x = 0, y = 0, x_res =0, y_res = 0
core A
atomic.Store(&x, 1)
if y == 0 {
x_res = 1
}
core B
atomic.Store(&y, 1)
if x == 0 {
y_res = 1
}因為 core B 收到 core B 的 PrWr,core B 不會馬上標記 I,而是放到 invalidation queue,若 core B 執行 LOAD x 時,invalidation queue 還沒清空,core B 就會讀到 core A 更新前的值,仍可能出現 x_res & y_res 都是 1 的情況。
而 atomic.Load 會在 LOAD 之前設置 barrier 強制檢查 invalidation queue 中有沒有該 cache line,有的話更新成 I 狀態,並確保讀到最新資料,因此:
x = 0, y = 0, x_res =0, y_res = 0
core A
atomic.Store(&x, 1)
if atomic.Load(&y) == 0 {
x_res = 1
}
core B
atomic.Store(&y, 1)
if atomic.Load(&x) == 0 {
y_res = 1
}就絕對不會出現 x_res & y_res 同時為 1 的情況。
note: 雖然說 invalidation queue 稱作 queue,但檢查 cache line 在不在 invalidation queue 本質上是用狀態碼,而不是真的 scan queue。
go 的 atomic 跟 rust 的 atomic 之間有什麼不一樣?
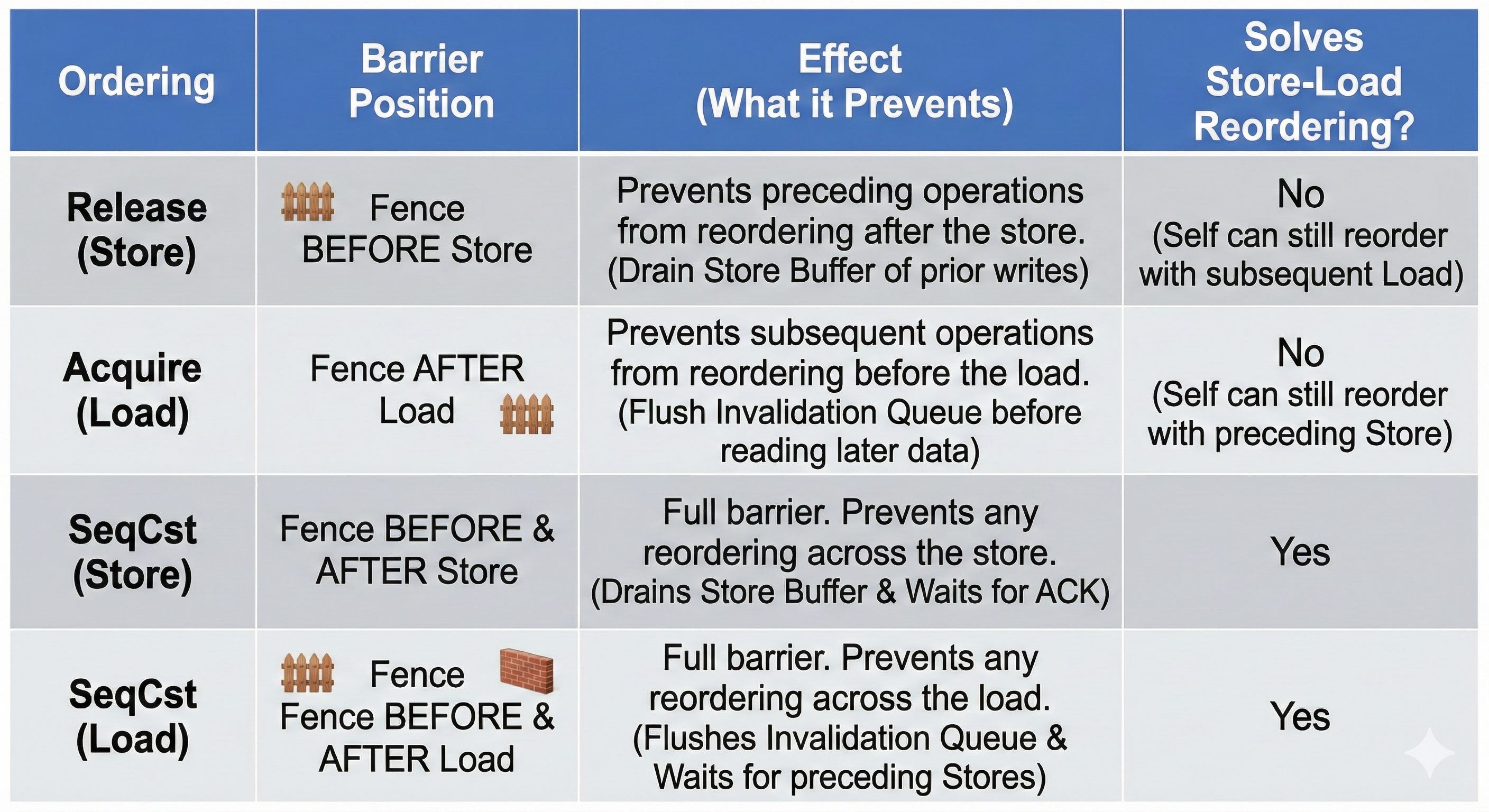
go 的 atomic.Load & atomic.Store 本質上類似 SeqCst ordering,也就是在 STORE 之後,LOAD 之前設下 barrier,這樣可保證寫入方的指令不會被 reorder。
但像 rust 更底層的語言就支援其他 atomic barrier 機制,例如 Release/Acquire ,Release 是在 STORE 之前設置 barrier,Acquire 在 LOAD 之前設下 barrier。
例如下面案例:
x = 0, y = 0, x_res =0, y_res = 0
core A
atomic.Store(&x, 1, Release)
if atomic.Load(&y, Acquire) == 0 {
x_res = 1
}
core B
atomic.Store(&y, 1, Release)
if atomic.Load(&x, Acquire) == 0 {
y_res = 1
}會 race condition,因為 Release 只保證 STORE 1 => x 之前清空 store buffer,STORE 1 => x 可被放到 store buffer 後就往下執行,會發生 Store-Load Reorder 的情況。
因此 Release/Acquire 只能用在單向傳輸的情況,例如:
core A
flag = 0, x = 0
core A
x = 1
atomic.Store(&flag, 1, Release)
core B
for atomic.Load(&flag, Acquire) { print(x) }core B 的 stdout 一定是輸出 1
最後 rust 還有 Relaxed Ordering 不設置任何 barrier 但保證這次指令是原子性的,例如 atomic.Add(&x, 1, Relaxed)。
Go 與 Rust 範例代碼
下面 go 代碼展示兩個 thread 競爭 flag 的代碼:
由於正確加上 atomic,所以不會 break,可以試著做以下調整:
移除 atomic.Load,跑一陣子後有機會 break
移除 atomic.Store & atomic.Load 跑一下後很快就會 break
func main() {
for i := 0; ; i++ {
x, y, r1, r2 := int64(0), int64(0), int64(0), int64(0)
wg := sync.WaitGroup{}
wg.Add(2)
go func() {
defer wg.Done()
atomic.StoreInt64(&x, 1)
if atomic.LoadInt64(&y) == 0 { // if Store-Load reordering occurs, y will read 0
r1 = 1
}
}()
go func() {
defer wg.Done()
atomic.StoreInt64(&y, 1)
if atomic.LoadInt64(&x) == 0 { // if Store-Load reordering occurs, x will read 0
r2 = 1
}
}()
wg.Wait()
if r1 == 1 && r2 == 1 {
fmt.Printf("Observed reordering at iteration %d: r1=%d, r2=%d\n", i, r1, r2)
break
}
}
}
下面 rust 代碼展示不同 atomic ordering 寫法:
使用 Release & Acquire 實現單向的 flag 傳輸,用兩個 thread 按照順序印出 1 ~ 1000
use std::sync::Arc;
use std::sync::atomic::{AtomicBool, AtomicUsize, Ordering};
use std::thread;
fn main() {
let n = 1000;
let i = Arc::new(AtomicUsize::new(1));
let flag = Arc::new(AtomicBool::new(true));
let (i_a, flag_a) = (Arc::clone(&i), Arc::clone(&flag));
let t1 = thread::spawn(move || {
loop {
if flag_a.load(Ordering::Acquire) {
let current: usize = i_a.fetch_add(1,Ordering::Relaxed);
if current > n {
flag_a.store(false, Ordering::Release);
break;
}
println!("{}", current);
flag_a.store(false, Ordering::Release);
}
}
});
let (i_b, flag_b) = (Arc::clone(&i), Arc::clone(&flag));
let t2 = thread::spawn(move || {
loop {
if !flag_b.load(Ordering::Acquire) {
let current: usize = i_b.fetch_add(1,Ordering::Relaxed);
if current > n {
flag_b.store(true, Ordering::Release);
break;
}
println!("{}", current);
flag_b.store(true, Ordering::Release);
}
}
});
t1.join().unwrap();
t2.join().unwrap();
}