
How to Build a High-Performance TCP Server Part 1 - How Can a Single Server Handle Tens of Thousands of Concurrent Connections?
From the C10K Problem to epoll: A Deep Dive into the Performance Secrets of Nginx, Redis, and Rust Tokio

Nginx is renowned as a high-performance proxy server, while Redis stands as the king of caching databases. Both process individual requests with incredible speed because they almost entirely bypass disk I/O, the traditional bottleneck of system performance.
But what happens when a server is hit by a massive surge of concurrent requests?
Let’s explore how Nginx and Redis manage high-traffic spikes under the hood.
The C10K Problem: Why Do Servers Crash Under High Load?
When tens of thousands of client requests flood in simultaneously, even without disk bottlenecks, a server can still fail.
To return results, a server must establish a TCP connection for every request. A common “intuitive” approach is the Connection-Per-Thread model. Since each connection must transmit data without blocking others, the server creates one thread for every single connection. This leads to a massive number of threads, causing the CPU to struggle with constant Context Switching and exhausting system memory. This is the classic C10K problem: how can a single server handle 10,000 concurrent connections efficiently?
In a TCP server, the accept() system call establishes a connection, while read() and write() handle data. These operations behave differently depending on whether they use Blocking or Non-Blocking I/O.
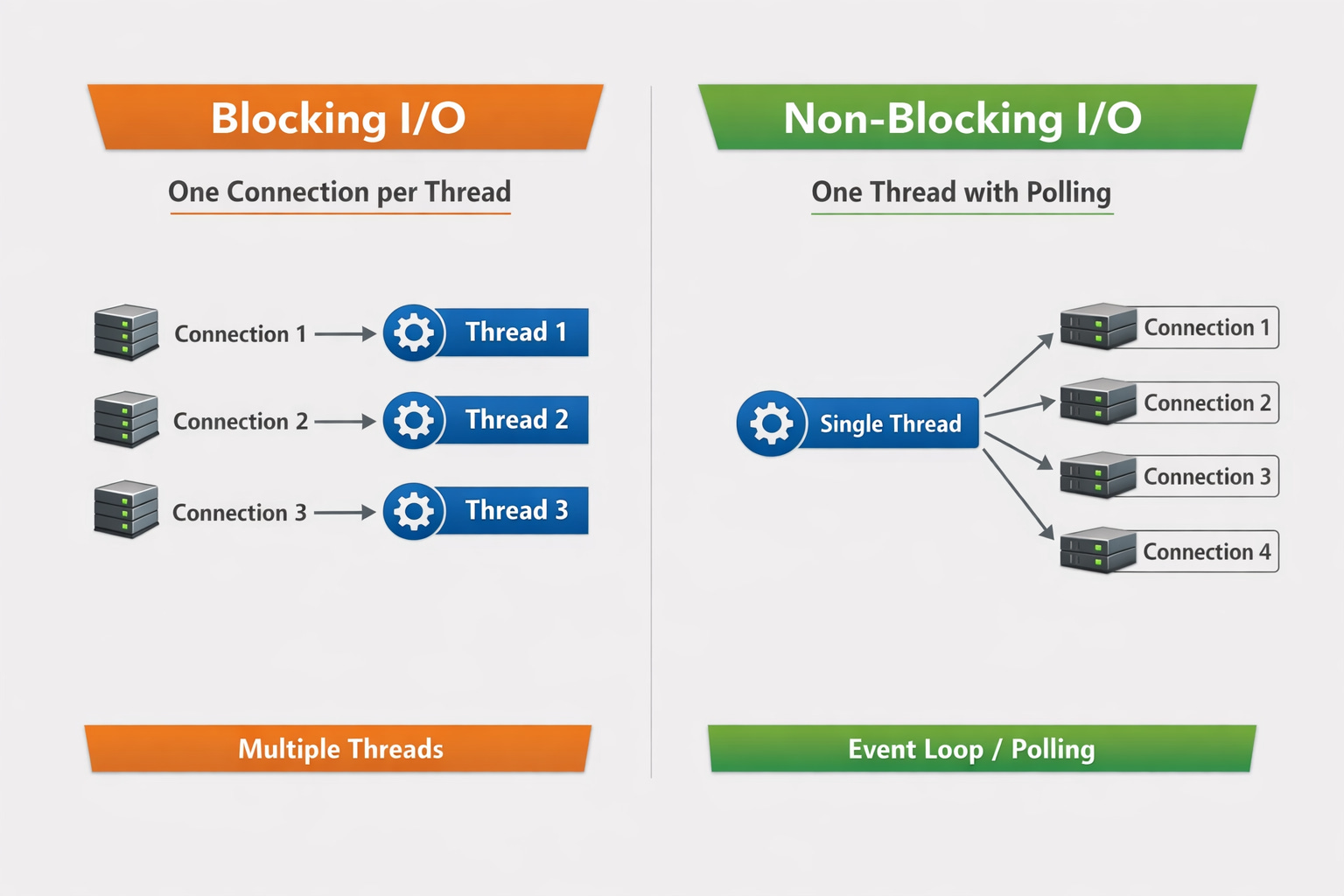
1. Blocking I/O (Connection-Per-Thread)
In Blocking I/O, if a read() call has no data to read, it “hangs” (blocks) until data arrives. Similarly, if the kernel’s write buffer is full, write() blocks until space becomes available. Because a thread is stuck waiting for one connection, it cannot handle others. Therefore, each connection requires its own dedicated thread, leading to the resource exhaustion mentioned above.
2. Non-Blocking I/O (One-Thread Polling)
In Non-Blocking I/O, read() or write() calls return an error immediately if no data is available or the buffer is full. A single thread can manage multiple connections by cycling through them—if the first connection has no data, the thread moves to the next without waiting.
However, this requires a Polling loop. The thread must repeatedly check whether each TCP connection is ready for I/O. Each check is a system call. If thousands of connections are idle, the thread wastes massive amounts of CPU cycles making useless system calls.
Efficient Management: I/O Multiplexing
To manage multiple Non-Blocking I/Os efficiently, we look to the Kernel. The Kernel doesn’t rely on polling; it uses Hardware Interrupts. For instance, when a Network Interface Card (NIC) receives a packet, it sends an interrupt signal to the CPU. The CPU pauses its current task, allows the Kernel to read the data into memory, and then notifies the relevant user-space process.
Since the Kernel can actively notify processes, we can use I/O Multiplexing. This allows a user-space process to ask the Kernel to monitor multiple TCP connections at once. The process “sleeps” (blocks) on a single system call and only wakes up when at least one connection is ready for I/O.
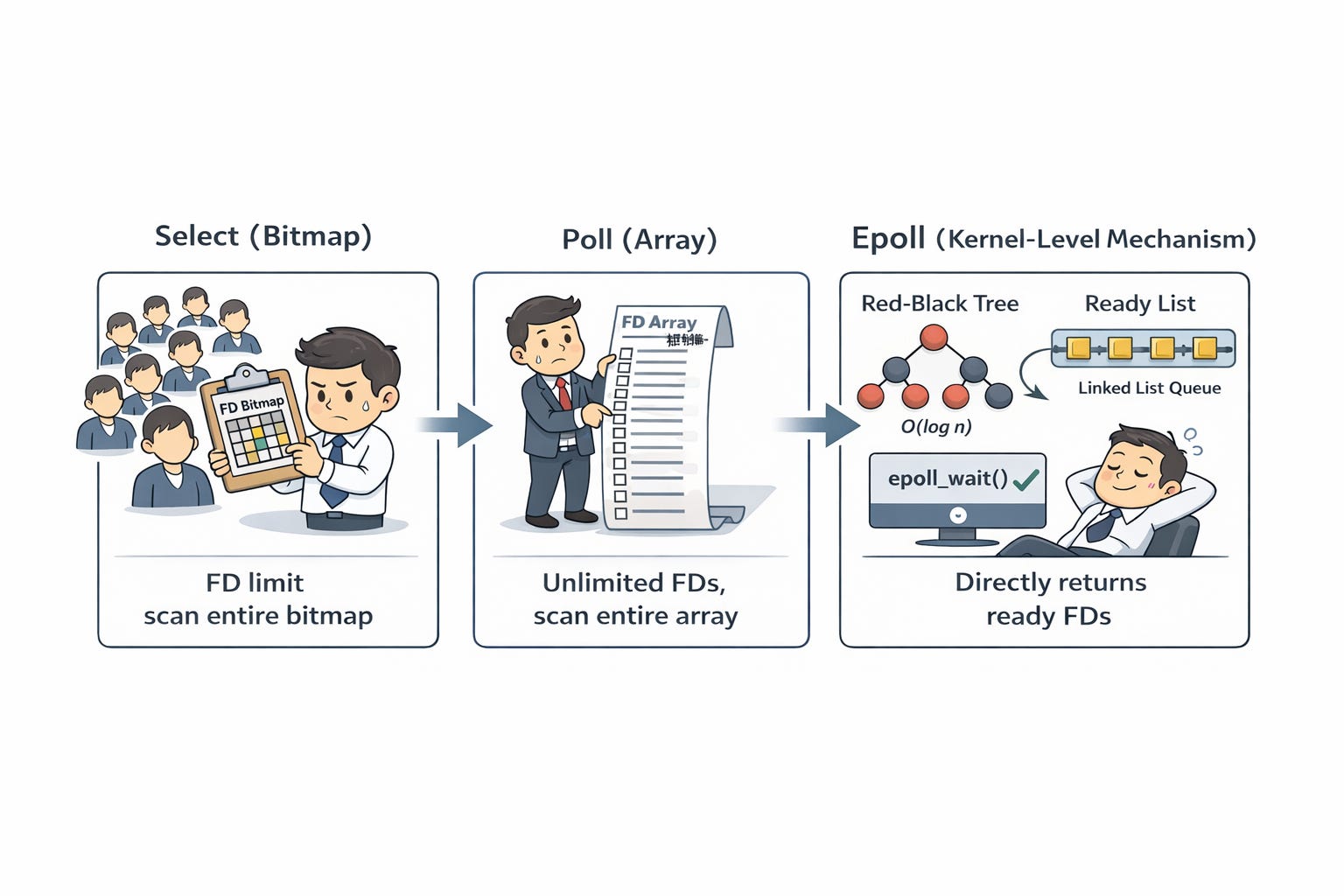
The Evolution: select, poll, and epoll
Early Kernel solutions like select used a bitmap to track connections. The process would block until a connection became active, at which point the Kernel would update the bitmap. However, select had a limited number of connections it could track, leading to the creation of poll, which used an array to remove that limit.
Despite the improvement, both had two major flaws:
The entire data structure (bitmap or array) had to be copied from user space to kernel space every time.
When the process woke up, it had to scan the entire structure to find which specific connection was ready.
The Superior Mechanism: epoll
epoll is an internal Kernel structure. Instead of passing a bitmap every time, you use epoll_create() to let the Kernel maintain a Red-Black Tree and a Double Linked List.
Red-Black Tree: Stores the TCP connections. Adding or removing a connection is
O(log n), making it ideal for frequent changes.Double Linked List (Ready List): When a connection receives data, the Kernel’s callback function places it into this list.
When a process calls epoll_wait(), it blocks. Once a connection is ready, the Kernel wakes the process, which simply retrieves the ready connections from the linked list. There is no need to scan thousands of idle connections.
Since epoll uses a double linked list as a ready queue, it supports two triggering modes:
Level-Triggered (LT):
As long as there is unread data on the connection,epoll_wait()will continue to return the file descriptor. In other words, the connection remains in the ready list until all available data has been read.Edge-Triggered (ET):
Events are triggered only when the state changes. When new data arrives, the connection is added to the ready list, and onceepoll_wait()returns it, it is removed. It will not be added again until new data arrives.
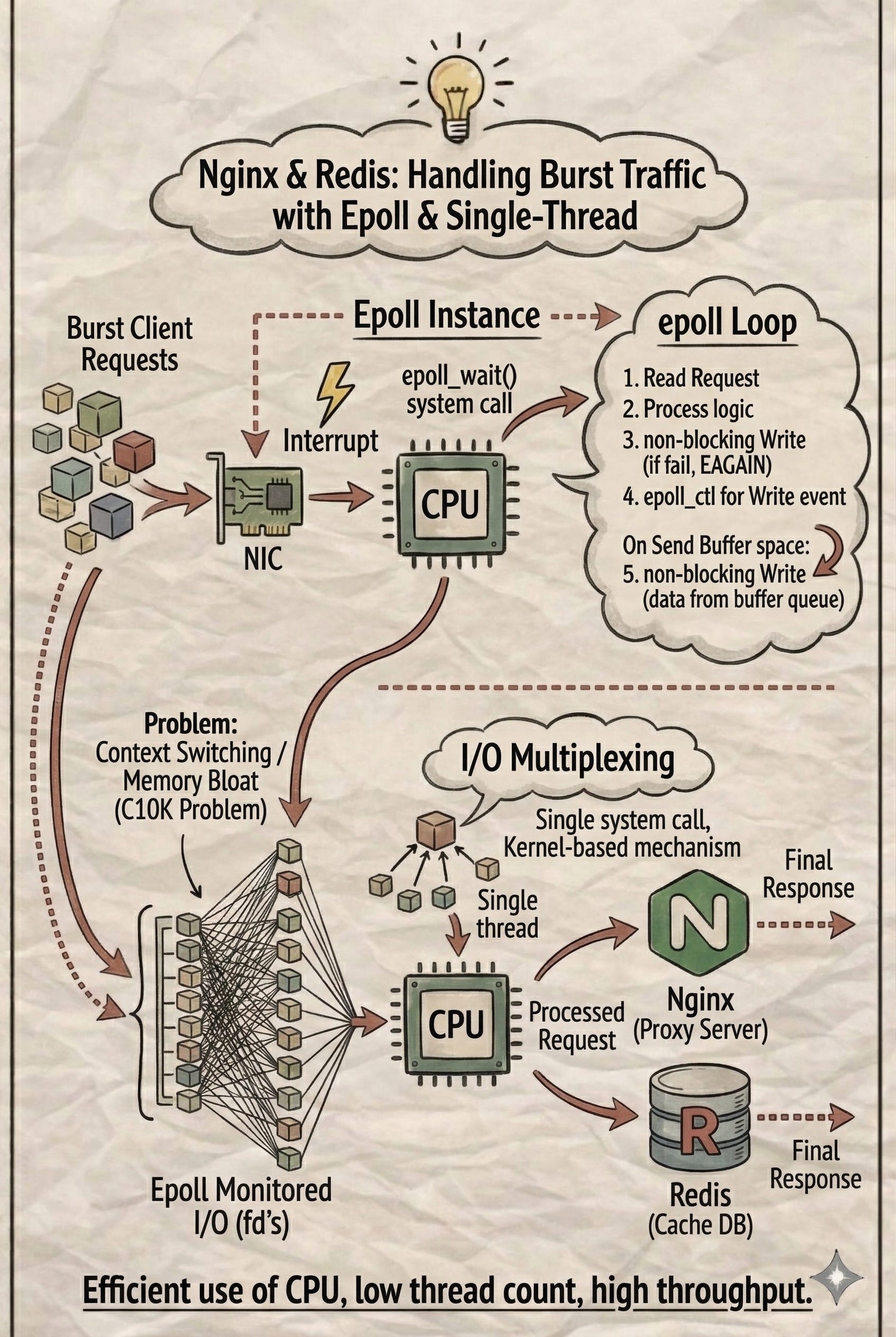
How Nginx and Redis Use Epoll
Both Nginx and Redis typically use a single-threaded event loop (or one per CPU core) to run epoll_wait(). This avoids the complexities of multi-threaded data synchronization. The secret to their speed is that they never do anything that blocks the loop.
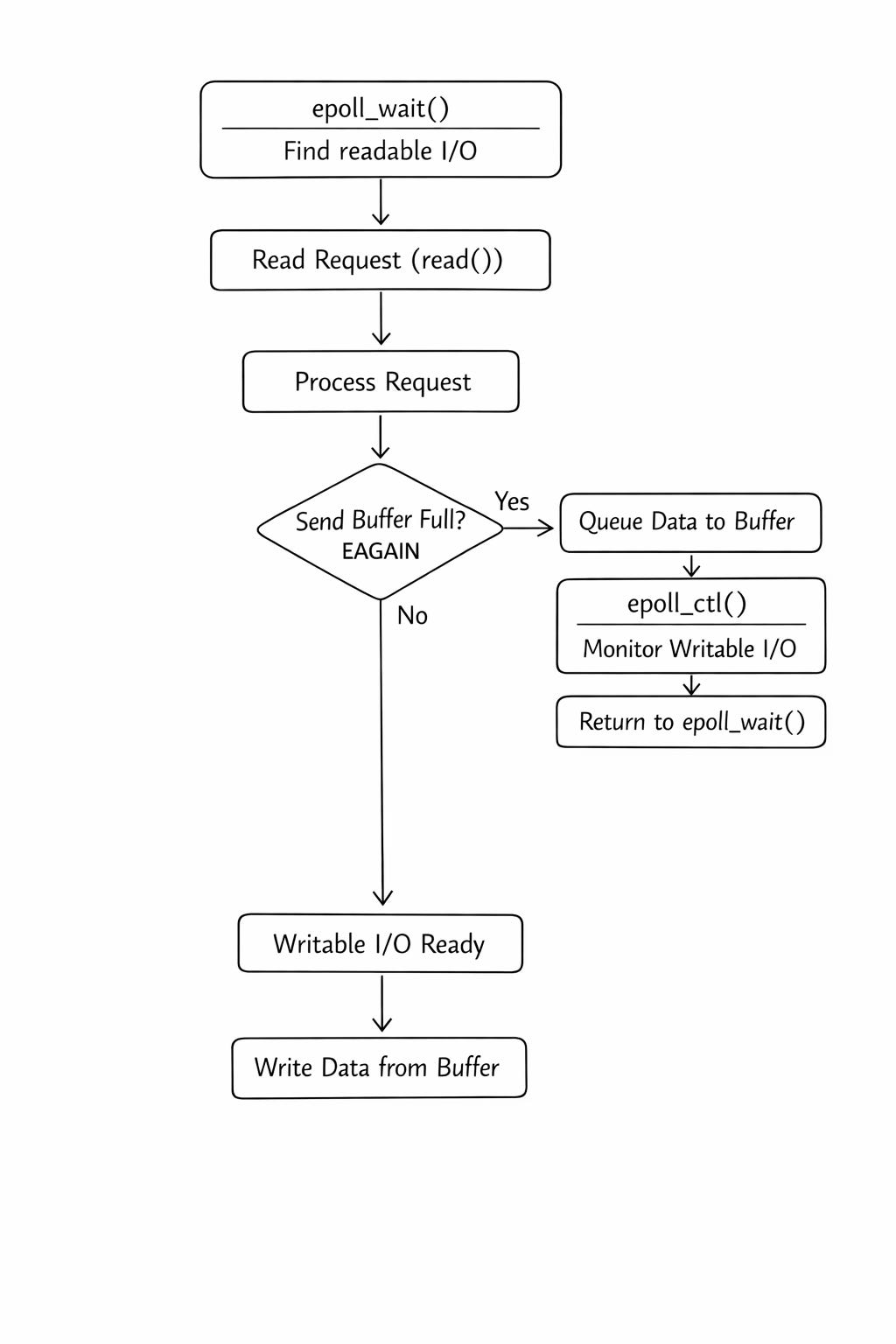
The Epoll Loop Workflow:
Call
epoll_wait()to find ready I/Os andread()the requests.Process the logic.
Call
write()to return results. If the kernel send buffer is full, the non-blockingwrite()returns an error.Instead of waiting, the server moves the data to a temporary buffer queue, tells
epollto watch for a “writable” event, and moves to the next request.Once the buffer has space,
epoll_wait()triggers, and the server finishes thewrite().
By only executing read or write when the Kernel confirms they are ready, CPU utilization is maximized and memory usage remains low.
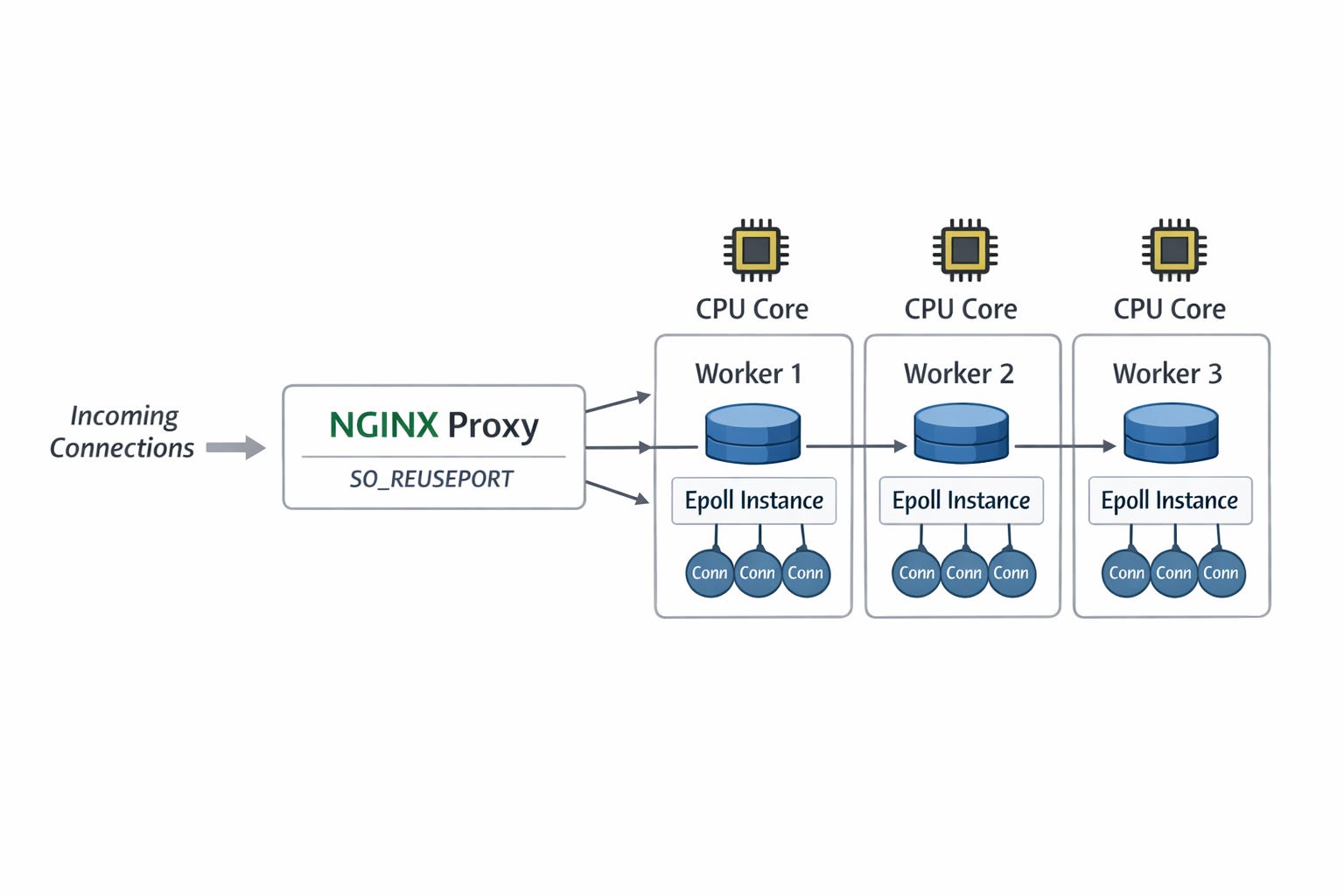
Additionally, as a proxy server, Nginx improves request forwarding throughput by leveraging the kernel’s SO_REUSEPORT option.
This allows multiple processes to bind to the same TCP port, with the kernel automatically distributing incoming connections across different server sockets. Each thread (or process) then manages its own set of connections using an independent epoll instance, enabling a concurrent architecture.
How to Implement a High-Performance TCP Server using Epoll: A Case Study with Rust's Tokio
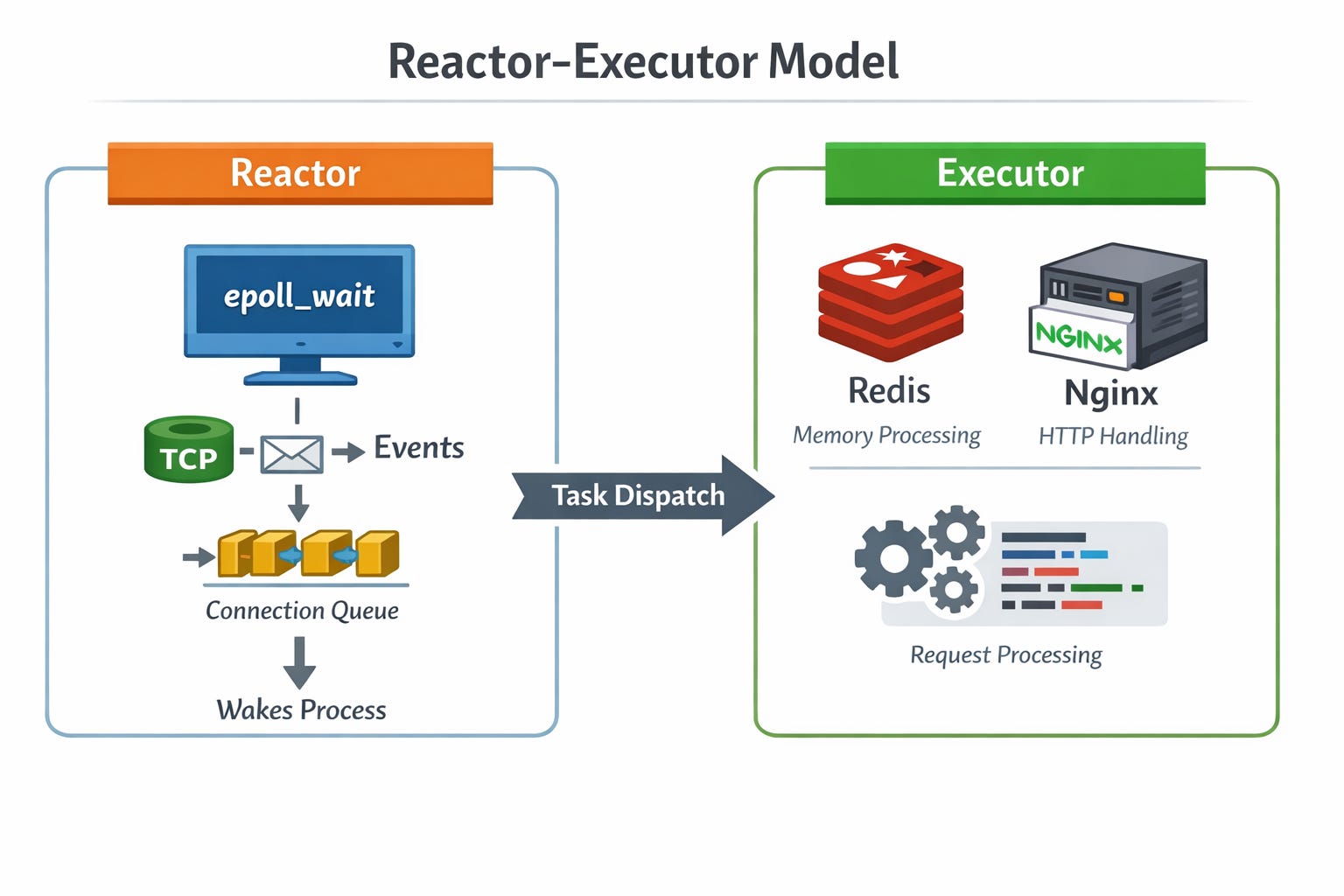
A common pattern for implementing an epoll loop like Nginx and Redis is the Reactor–Executor pattern :
Reactor: Manages event states (via
epoll_wait) and wakes up tasks when I/O is ready.
Executor: The core engine that processes the logic (e.g., Redis memory operations or Nginx HTTP parsing).
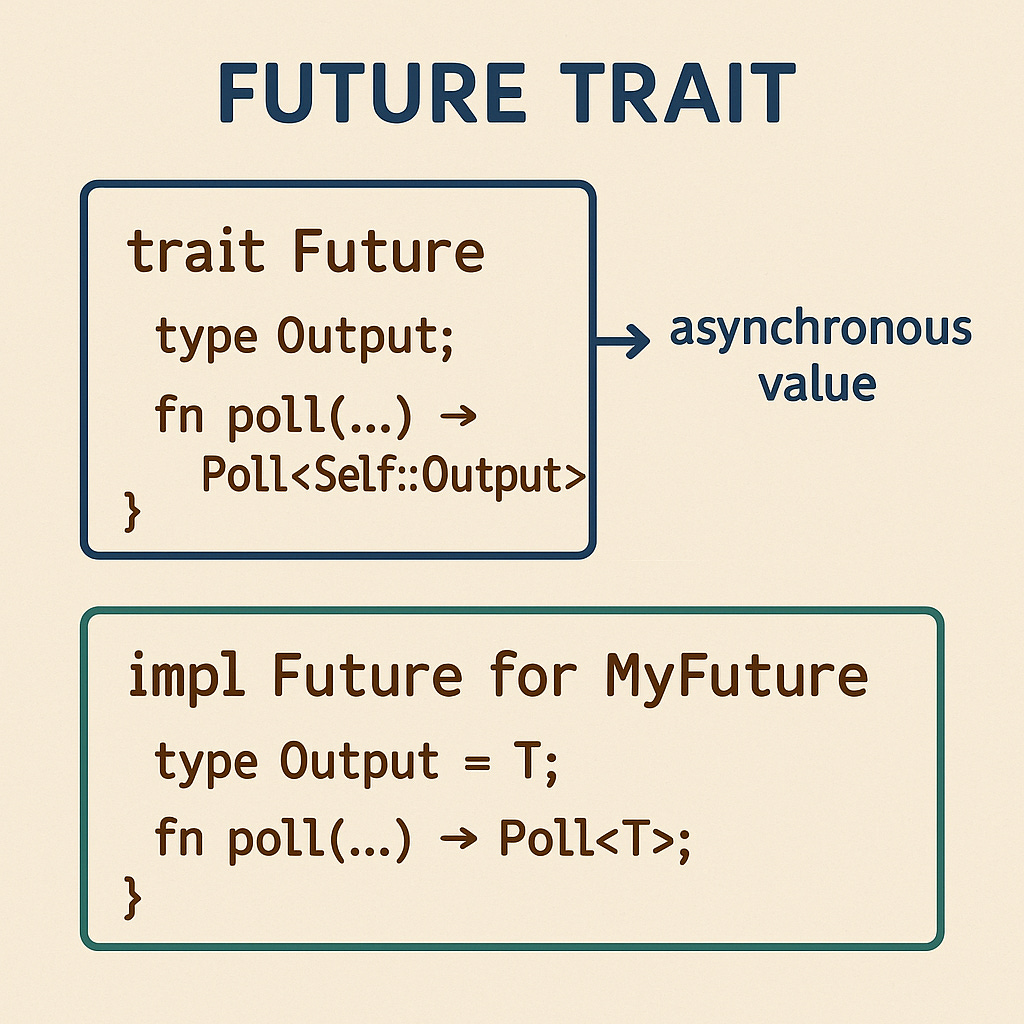
In the Rust ecosystem, the event states managed by the reactor are abstracted into the Future trait. This interface represents an asynchronous operation, where calling poll drives the internal logic of the Future. If the data isn't ready, it returns Poll::Pending and registers itself with the Reactor to be woken up later.
Example: A Simplified Reactor-Executor
First, we define a basic SleepFuture to simulate I/O wait:
struct SleepFuture {
deadline: Instant,
}
impl SleepFuture {
fn new(duration: Duration) -> Self {
SleepFuture {
deadline: Instant::now() + duration,
}
}
}
impl Future for SleepFuture {
type Output = ();
fn poll(self: Pin<&mut Self>, _cx: &mut Context) -> Poll<()> {
if Instant::now() >= self.deadline {
Poll::Ready(())
} else {
Poll::Pending
}
}
}
async fn send_request() -> i32 {
SleepFuture::new(Duration::from_secs(2)).await;
1 + 1
}
fn process_response(val: i32) {
println!("處理結果: {}", val);
}Next, we implement the event loop logic for the Reactor and Executor. The Reactor polls futures and sends ready results to the Executor via a channel:
type BoxFuture = Pin<Box<dyn Future<Output = i32> + Send>>;
fn reactor(futures: Vec<BoxFuture>, tx: mpsc::Sender<i32>) {
let waker = Waker::noop();
let mut cx = Context::from_waker(&waker);
// 把每個 future 包成 Option,完成後設為 None
let mut tasks: Vec<Option<BoxFuture>> = futures.into_iter().map(Some).collect();
let total = tasks.len();
let mut done_count = 0;
loop {
for task in tasks.iter_mut() {
if let Some(fut) = task {
if let Poll::Ready(val) = fut.as_mut().poll(&mut cx) {
tx.send(val).unwrap(); // Ready!丟給 queue 裡面給 executor
*task = None;
done_count += 1;
}
}
}
if done_count >= total {
break;
}
thread::sleep(Duration::from_millis(100)); // 簡單的 polling 間隔
}
}
fn executor(rx: mpsc::Receiver<i32>, total: usize) -> thread::JoinHandle<()> {
thread::spawn(move || {
let mut done = 0;
while done < total {
let val = rx.recv().unwrap();
process_response(val);
done += 1;
}
println!("executor: 全部處理完成");
})
}
fn main() {
let (tx, rx) = mpsc::channel();
let futures: Vec<BoxFuture> = vec![
Box::pin(send_request()),
Box::pin(send_request()),
];
let total = futures.len();
// executor worker thread:等 reactor 丟結果過來就執行
let handle = executor(rx, total);
let start = Instant::now();
// reactor:poll futures,ready 後透過 channel 丟給 executor
reactor(futures, tx);
handle.join().unwrap();
println!("全部完成,耗時: {:?}", start.elapsed());
}
The above code demonstrates the abstraction capability of the Future trait: it encapsulates all operations as asynchronous behaviors and allows developers to define when state transitions occur.
By combining this with different underlying event loop mechanisms, one can swap out various Reactor–Executor implementations without modifying the core business logic.
Tokio’s Real-World epoll Implementation
With the basic concept of the Reactor-Executor pattern in mind, let’s look at a simple TCP Echo Server implemented with Tokio :
use tokio::net::TcpListener;
use tokio::io::{AsyncReadExt, AsyncWriteExt};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let listener = TcpListener::bind("127.0.0.1:8080").await?;
loop {
let (mut socket, _) = listener.accept().await?;
tokio::spawn(async move {
let mut buf = [0; 1024];
// In a loop, read data from the socket and write the data back.
loop {
let n = match socket.read(&mut buf).await {
// socket closed
Ok(0) => return,
Ok(n) => n,
Err(e) => {
eprintln!("failed to read from socket; err = {:?}", e);
return;
}
};
// Write the data back
if let Err(e) = socket.write_all(&buf[0..n]).await {
eprintln!("failed to write to socket; err = {:?}", e);
return;
}
}
});
}
}When you use the #[tokio::main] macro, it initializes a Runtime Object. The block_on function waits for all future events to complete. Since the primary future is a TCP server handling new connections, the runtime remains active as long as the server is running.
Under the hood, #[tokio::main] expands to:
epoll_create(): Establishes the epoll instance.Thread Pool: Creates worker threads (Executors).
Timer Wheel: Manages
sleepandtimeoutevents.
fn main() {
let runtime = tokio::runtime::Runtime::new().unwrap();
// 1. epoll_create() → create epoll instance
// 2. create thread pool → worker threads
// 3. create timer wheel → manage sleep/timeout
runtime.block_on(async {
let listener = TcpListener::bind("127.0.0.1:8080").await.unwrap();
// ...
});
// block_on start reactor 的 event loop
} How Tokio Manages I/O via epoll
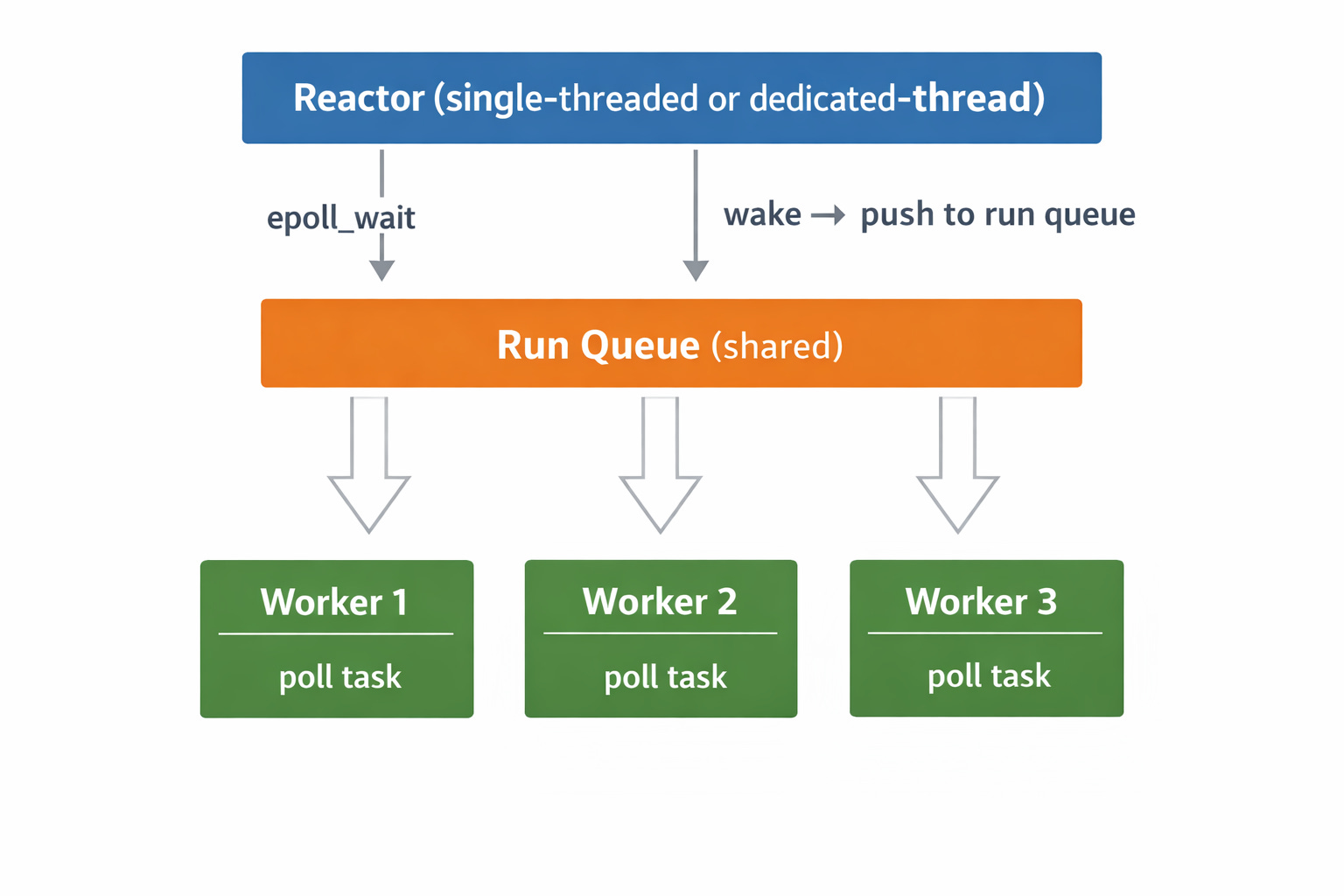
Tokio’s Reactor module uses epoll to manage network I/O. When a connection becomes readable, it is pushed into a queue for an Executor to process.
# Conceptual code example
impl Reactor {
fn run(&mut self) {
loop {
let timeout = self.nearest_timer_deadline();
let ready_fds = epoll_wait(self.epoll_fd, timeout);
for (fd, token) in ready_fds {
self.run_queue.push(token.task_id);
}
}
}
}
Tokio also wraps TCP connections into Non-Blocking I/O + epoll-registered Futures. When poll is called, it attempts a non-blocking read. If no data is available, it registers the file descriptor with epoll and returns Pending:
# Conceptual code example
impl Future for TcpReadFuture {
fn poll(mut self: Pin<&mut Self>, cx: &mut Context) -> Poll<Vec<u8>> {
match non_blocking_read(self.fd, &mut self.buf) {
Ok(data) => Poll::Ready(data), // Data available, return immediately
Err(WouldBlock) => {
if !self.registered {
// Retrieve reactor via thread-local and register to epoll
reactor.register(self.fd, Interest::READ, cx.waker().clone());
self.registered = true;
}
Poll::Pending // Tell the executor: "Not ready, go handle other tasks"
}
}
}
}When executing an await (e.g., socket.read(&mut buf).await), the compiler generates code conceptually similar to:
# Conceptual code example
loop {
match future.poll(cx) {
Poll::Ready(val) => break val,
Poll::Pending => {
return Poll::Pending;
}
}
}During the poll call, if the future involves a connection that is not yet ready (e.g., a non-blocking socket), that connection will be registered with epoll (via the runtime’s reactor) so it can be monitored for readiness.
The Role of tokio::spawn
In Tokio, the executor schedules and polls futures, and it is backed by a pool of worker threads.
It is important to note that tokio::spawn(async move { ... }) does not create a new kernel thread. Instead, it enqueues the async task into the runtime’s task queue. Worker threads then pick up and execute these tasks by polling their associated futures.
Each worker thread runs a loop similar to this:
# Conceptual code example
fn worker_thread(run_queue: Arc<SharedQueue>, tasks: Arc<TaskMap>) {
loop {
let task_id = run_queue.pop(); // Blocks if queue is empty
let task = tasks.get(task_id);
match task.poll(&mut cx) {
Poll::Ready(()) => { tasks.remove(task_id); }
Poll::Pending => { /* Waker is registered, wait for next wake-up */ }
}
}
}Worker threads are configured when the runtime is created:
#[tokio::main(flavor = “multi_thread”, worker_threads = 4)]
async fn main() {
// your async code
}Nested Future Task
In the TCP Echo server above, each task handled by a worker thread is a nested future structure that performs connection read and write operations:
spawnFuture (ReadLoopFuture)└── socket.read().await(TcpReadFuture)└── non_blocking_read() → WouldBlock → Register epoll
└── socket.write().await(TcpWriteFuture)└── non_blocking_write() → WouldBlock → Register epoll
If socket.read() has no data, it is placed in epoll to await notification from the Reactor. The Executor, receiving a Pending status, moves on to the next connection’s future. Once the Reactor wakes the future, the process continues to the write stage. If the write buffer is full, it returns Pending again, waiting for the next “writable” signal from the Reactor.
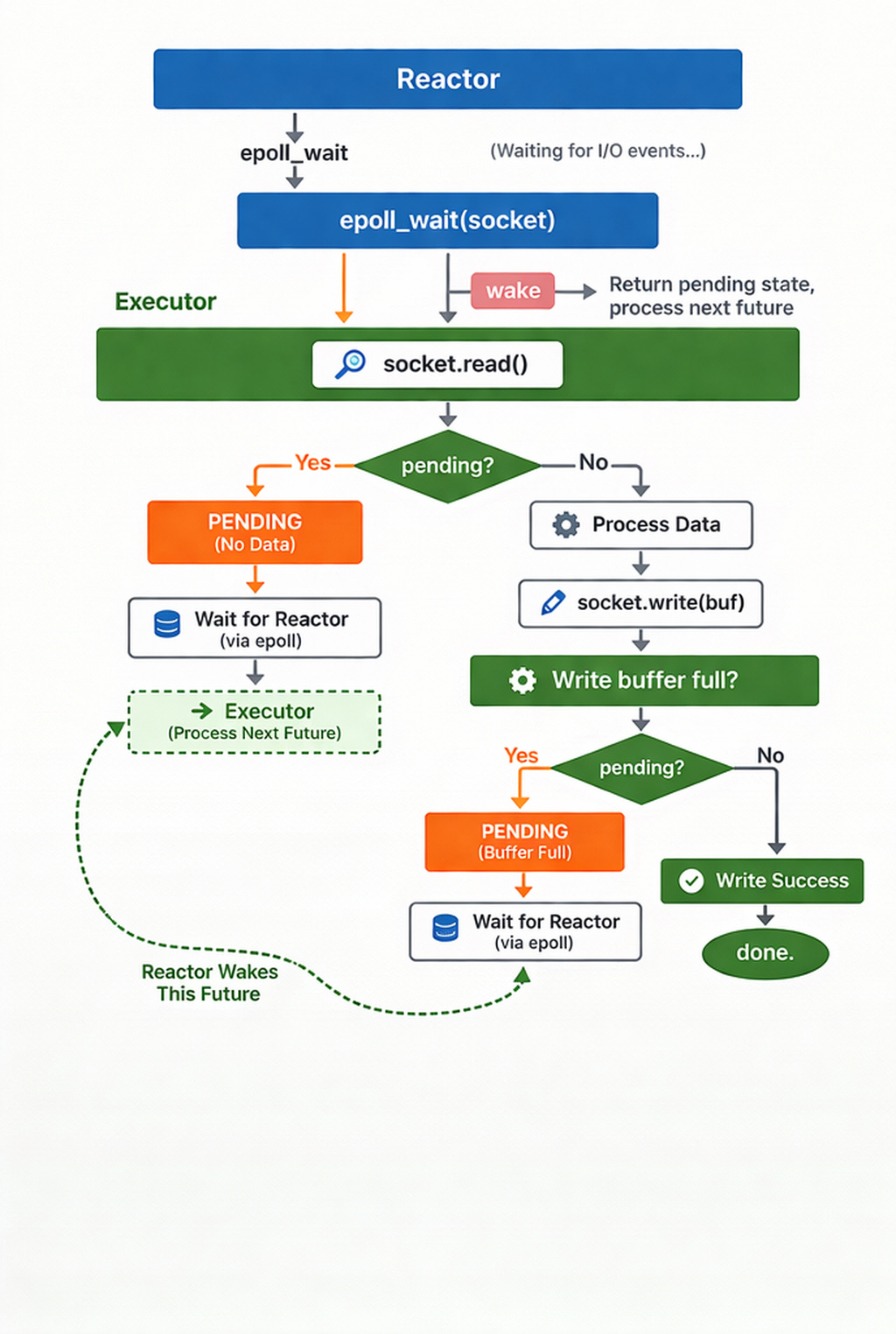
Finally, the overall Tokio runtime architecture can be summarized as:
Preview of the next part:
Although epoll has been the preferred low-level technology for most high-performance servers, newer async I/O mechanisms have emerged as the kernel has evolved—most notably io_uring. Rust’s Tokio ecosystem also has implementations of async runtimes based on io_uring. In the next part, we will examine the performance limitations of epoll and how io_uring addresses them.