
How to Build a High-Performance TCP Server Part 2 – Is io_uring Always Faster Than epoll? A Deep Dive into System Internals.
From syscall overhead to shared memory queues: understanding the next evolution of Linux I/O

As mentioned in the previous episode, Nginx, Redis, and Rust’s Tokio all utilize non-blocking I/O combined with epoll to develop high-efficiency TCP servers. However, epoll has its drawbacks: when epoll_wait returns a ready connection, you still need to perform additional read or write system calls to move data. With high concurrency, the context switching between user space and kernel space significantly impacts performance.
io_uring is the kernel mechanism designed to solve this. But how do we read and write data without executing read & write system calls?
How to read/write without read & write system calls?
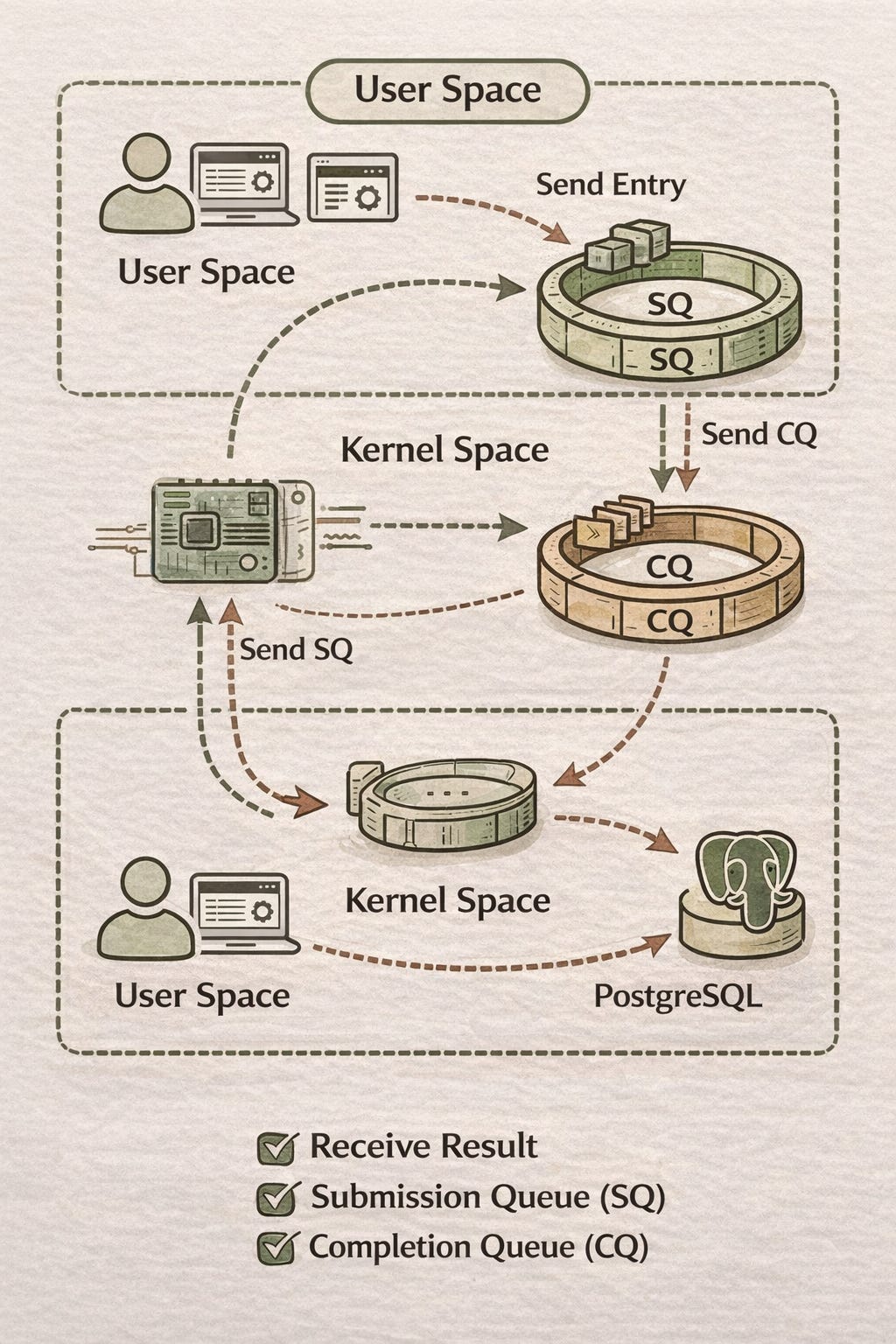
When using io_uring, the kernel establishes two queues:
Submission Queue (SQ): The user-space process places I/O operation requests (e.g., read, write) into this queue for the kernel to consume.
Completion Queue (CQ): The kernel places I/O completion notifications into this queue for the user-space process to consume.

Because of this, even blocking I/O becomes asynchronous with io_uring. Operations are encapsulated into entries placed in the SQ, and results are retrieved by consuming CQ entries. An entry contains these primary fields:
fd: The I/O object (e.g., TCP connection) ID in the kernel.
opcode: An enum for the entry type (e.g., read, write, or accept).
data pointer: A memory pointer where the kernel reads/writes data. Usually, a byte array is initialized in user space and its pointer is passed.
user_data: An identifier for the entry.
When a user-space process receives a “read complete” entry from the CQ, it needs to know which byte array to read from. Thus, the user_data in the CQ entry matches the SQ entry. For example, you can cast the pointer of the byte array into an int and store it in user_data:
// Create SQE (SQ entry)
struct request *req = malloc(sizeof(*req));
sqe->opcode = IORING_OP_READ;
sqe->fd = req->fd;
sqe->addr = (uint64_t)req->buf;
sqe->user_data = (uint64_t)req;
// Receive CQE (CQ entry), use user_data to restore the request buffer
struct request *req = (struct request *)cqe->user_data;Does sending entries to SQ & CQ require system calls?
While SQ and CQ are kernel objects, the kernel uses mmap to map them into user space, allowing user-space processes to access them directly without going through system calls. To explain mmap, we must first mention Virtual Memory Space:
Virtual Memory Space
Every user-space process has its own page table that records accessible memory addresses (e.g., 0x000 ~ 0x3FF represents 1KB). However, these page table addresses are not physical memory locations. The kernel uses a mapping mechanism to map virtual memory addresses to physical ones—this is Virtual Memory Mapping technology.

Page Fault & mmap
The benefit of using Virtual Memory is that when a process executes malloc(1G), it doesn’t need 1GB of RAM immediately. Instead, it simply records in the page table that the range 0x00000000 ~ 0x3FFFFFFF is accessible. When the CPU reads a virtual memory address and finds no corresponding physical memory, it triggers a Page Fault. Subsequently, the kernel allocates resources and establishes a link based on the actual size used (the minimum unit being 4KB)—essentially a lazy load technique.
The mmap technique allows a Page Fault to read data from a specified physical memory and establish a link. For instance, by mapping the process’s virtual memory space 0x000 ~ 0x3FF to the io_uring queue in kernel memory, a CPU read of 0x000 ~ 0x3FF that triggers a Page Fault will directly read the physical memory location of the kernel io_uring queue, rather than being allocated random blank physical memory.
Consequently, the process can directly access the kernel io_uring queue and send or read entries without through system calls.
Is there overhead in using queues?
Using a doubly linked list as a queue requires locking to handle concurrent push and pop operations safely. io_uring uses a Ring Buffer with a fixed-size array and two atomic indices (head and tail) to achieve lock-less operations:

Example Implementation (Rust):
use std::sync::atomic::{AtomicU64, Ordering};
const SIZE: usize = 8; // Must be a power of 2
struct RingBuffer {
buf: [i64; SIZE],
head: AtomicU64, // Consumer index
tail: AtomicU64, // Producer index
}
impl RingBuffer {
fn new() -> Self {
RingBuffer {
buf: [0; SIZE],
head: AtomicU64::new(0),
tail: AtomicU64::new(0),
}
}
// Producer side
fn push(&mut self, val: i64) -> bool {
let tail = self.tail.load(Ordering::Acquire);
let head = self.head.load(Ordering::Acquire);
if tail - head == SIZE as u64 {
return false; // Full
}
self.buf[(tail & (SIZE as u64 - 1)) as usize] = val;
self.tail.store(tail + 1, Ordering::Release);
true
}
// Consumer side
fn pop(&mut self) -> Option<i64> {
let head = self.head.load(Ordering::Acquire);
let tail = self.tail.load(Ordering::Acquire);
if head == tail {
return None; // Empty
}
let val = self.buf[(head & (SIZE as u64 - 1)) as usize];
self.head.store(head + 1, Ordering::Release);
Some(val)
}
}Furthermore, arrays are contiguous. For the CPU, a single cache access can fetch the entire structure. Conversely, linked list nodes might be scattered, causing multiple cache misses.
Besides queue optimization, what other performance boosts does io_uring offer?
Although read & write system calls are gone, io_uring still needs other calls, like io_uring_enter to notify the kernel to process tasks. However, this is still more efficient than epoll:
epoll:
epoll_wait+read/writesystem calls.io_uring:
io_uring_entertriggers the kernel and waits for CQ entries.
SQPOLL Mode for Zero I/O System Calls
To achieve zero I/O system calls, io_uring supports the SQPOLL mode. In this mode, the kernel uses an additional kernel thread to continuously poll the SQ. The user-space process does not need to execute io_uring_enter; it only needs to continuously poll the CQ. The downside is that if there is no data in the CQ, the process will perform many "useless" pulls. Therefore, SQPOLL is suitable for high-intensity, low-latency request scenarios.
IOPOLL Mode for Hardware Interrupt Optimization
The second optimization concerns hardware interrupts. io_uring still relies on hardware interrupts to signal completion, after which the kernel places the I/O results into the CQ.
However, hardware interrupts are not free. When the CPU receives an interrupt, it must first execute the interrupt handler. In addition to pausing the current instruction, it also flushes subsequent instructions in the pipeline. After handling the interrupt, execution resumes from the interrupted instruction address, and the following instructions are decoded and refilled into the pipeline.
If a large number of interrupts arrive in a short period, the CPU repeatedly flushing its pipeline becomes costly. To mitigate this, the kernel uses NAPI to handle network packet interrupts. After receiving the first interrupt, it switches to a polling mode, draining packets from the NIC in batches to avoid a burst of interrupts triggered by incoming traffic.
However, NAPI is primarily designed for network packet processing. When io_uring is used for file I/O (e.g., databases), a surge of read operations can still generate a large number of interrupts. To address this, io_uring provides the IO_POLL mode, which bypasses interrupts entirely and continuously polls the device for completion events.
Real-world Application: PostgreSQL 18
Databases perform frequent File I/O. PostgreSQL 18 introduced an async I/O mechanism with two modes:
worker (default): Delegates
read()/write()to another process. Boosts read-heavy query performance by ~1.5x.io_uring: Uses
io_uringfor I/O. Boosts read-heavy performance by ~2.7x.
Note: Since io_uring is asynchronous, PG warns that EXPLAIN ANALYZE for I/O timing may become less accurate.

ref: https://pganalyze.com/blog/postgres-18-async-io
epoll vs. io_uring benchmark - monoio vs. tokio
In Rust, the Future abstraction allows swapping runtimes easily. You can refer to the previous article for an introduction to the Future abstraction. monoio is built on io_uring, and its TCP echo server code looks nearly identical to tokio:
use monoio::{
io::{AsyncReadRent, AsyncWriteRentExt},
net::{TcpListener, TcpStream},
};
#[monoio::main(driver = "fusion")]
async fn main() {
// tracing_subscriber::fmt().with_max_level(tracing::Level::TRACE).init();
let listener = TcpListener::bind("127.0.0.1:50002").unwrap();
println!("listening");
loop {
let incoming = listener.accept().await;
match incoming {
Ok((stream, addr)) => {
println!("accepted a connection from {addr}");
monoio::spawn(echo(stream));
}
Err(e) => {
println!("accepted connection failed: {e}");
return;
}
}
}
}
async fn echo(mut stream: TcpStream) -> std::io::Result<()> {
let mut buf: Vec<u8> = Vec::with_capacity(8 * 1024);
let mut res;
loop {
// read
(res, buf) = stream.read(buf).await;
if res? == 0 {
return Ok(());
}
// write all
(res, buf) = stream.write_all(buf).await;
res?;
// clear
buf.clear();
}
}
To evaluate the performance of io_uring and epoll, I built a project called play_iouring, using the monoio and tokio libraries for benchmarking:
TCP echo server: tested with 10, 100, and 1000 concurrent TCP clients
File I/O: concurrent read/write on 100 files, each with 64 KB per operation
### File I/O (100 files, 64 KiB each)
| Benchmark | monoio | tokio | Δ |
|---------------|------------|------------|----------------|
| Write (100 files) | ~1.32 ms | ~1.95 ms | monoio ~1.5x faster |
| Read (100 files) | ~693 µs | ~1.87 ms | monoio ~2.7x faster |
### TCP Echo
| Benchmark | monoio | tokio | Δ |
|--------------------|------------|------------|----------|
| 10 clients | ~4.12 ms | ~3.98 ms | ~equal |
| 100 clients | ~26.6 ms | ~27.1 ms | ~equal |
| 1000 clients | ~292 ms | ~330 ms | monoio slightly faster |File I/O shows a significant improvement. The reason is that Tokio does not use epoll to manage file I/O; instead, it relies on worker threads with blocking I/O. In contrast, Monoio uses io_uring for file operations, which substantially reduces system call overhead. Therefore, file I/O is not a valid comparison between epoll and io_uring.
For the TCP echo workload, performance is nearly identical. The primary advantage of io_uring lies in reducing system calls, but in the lifecycle of packet read/write, system calls are not the dominant cost. The bottleneck is the kernel’s network stack (e.g., packet parsing, firewall rules, etc.). With only 1000 concurrent clients, the system call overhead is not significant enough to create a noticeable difference.
Moreover, under single-machine testing with a large number of concurrent clients, limited CPU cores can skew the results. Therefore, this benchmark mainly demonstrates that epoll and io_uring deliver comparable performance under typical conditions.