
How to ACE the "Design a Rate Limiter" system design interview.
Rate Limiter Algorithm Explanation and Use Case Analysis

Rate limiting is a critical component of system design and a frequently asked topic in technical interviews. To provide a “100-point” answer when asked how to implement a rate limiter, you need to go beyond just listing algorithms and demonstrate a deep understanding of their trade-offs, business applications, and distributed system challenges.
Interviewer: How would you clearly explain the trade-offs and use cases of different rate limiting algorithms?
The first step is to categorize rate limiters based on their logic.
Time-Window Based Limiters
These allow N requests within a specified timeframe. They are generally divided into Fixed Window and Sliding Window.
Fixed Window: Requests are counted within fixed time intervals (e.g., 1:00–1:01, 1:01–1:02).
Pros: Extremely simple to implement by mapping timestamps to buckets.
Cons: The “Boundary Problem.” A burst of traffic can occur at the junction of two windows.
For example, if the limit is 100/min, a user could send 100 requests at 1:01:59 and another 100 at 1:02:00, effectively doubling the allowed rate in just two seconds.
Sliding Window: This tracks the exact arrival time of each request within the last
Xseconds.Implementation: You can use a Redis Sorted Set to store every request timestamp. Before checking the limit, you remove all timestamps older than the current window (
current_time-window_size).Trade-off: While this provides precise control and eliminates boundary bursts, the storage and processing costs are high for high-concurrency traffic.
Optimization: An “Approximated Sliding Window” can be used, which divides the window into
Nsmaller buckets. This sacrifices a bit of precision for high efficiency while still smoothing out the boundary spikes of the Fixed Window.
When to use Time-Window Limiters?
These are ideal for Quota Management where the goal is to limit total resource consumption over time.
Examples: Limiting a user to 10 SMS messages per hour or 1,000 API calls per day for a subscription tier.
The Downside:
If a user exhausts their 120-request-per-minute limit in the first 10 seconds, the server remains idle for the remaining 50 seconds. While acceptable for resource-intensive APIs (where waiting is a reasonable business constraint), this “forced idling” is detrimental to Service-Oriented APIs (e.g., payments or order placement), where every second of waiting could result in lost transactions or market opportunities.
Usage-Based Limiters: Token Bucket & Leaky Bucket
For service-based APIs, the goal is Traffic Shaping—maintaining a stable, continuous flow rather than just enforcing a hard time-range quota.
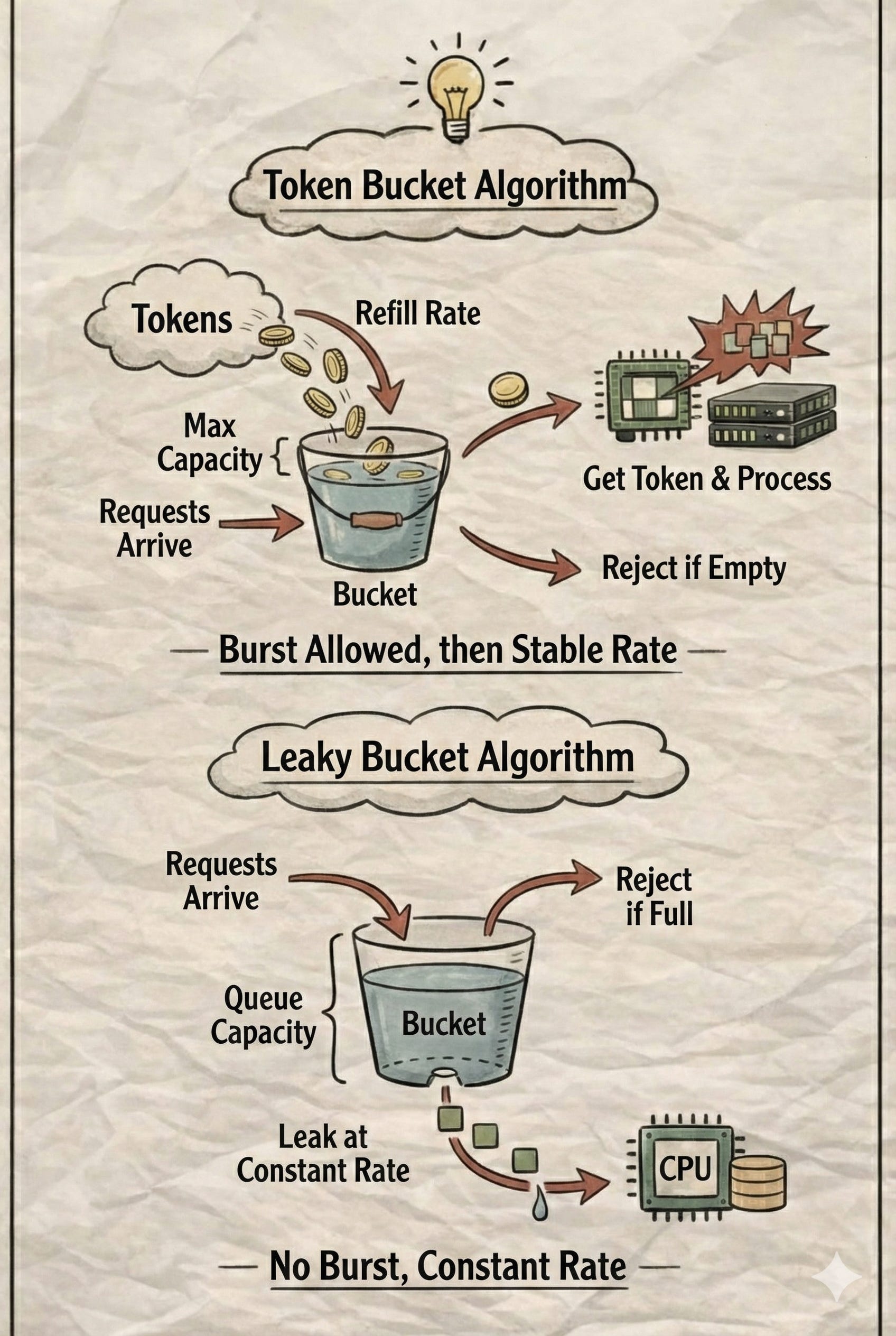
Token Bucket
Tokens represent the “capacity” to process a request. Tokens are added to the bucket at a fixed refill_rate (e.g., 1 token/sec).
Implementation Detail: An efficient way to implement this is not through a background thread, but by recording the
last_request_arrival_time. When a new request arrives, you calculate theelapsed_time, multiply it by therefill_rateto determine how many tokens to add, and cap it at the bucket’s maximum capacity.Behavior: For a limit of 120/min, you could set an initial capacity of 120 tokens and a refill rate of 2/sec. If a user exhausts all 120 tokens in the first second, they don’t have to wait 50 seconds; they can continue at a steady pace of 2 requests per second as tokens refill.
The “Burst” Logic: The Token Bucket algorithm allows for an initial burst of traffic; however, once a burst occurs, it immediately throttles the rate, converting the traffic into a stable flow.
Leaky Bucket
If your system strictly cannot allow bursts, you should use the Leaky Bucket instead. Imagine a bucket with a fixed capacity and a hole at the bottom. Requests enter the bucket and are "leaked" (processed) at a constant, predetermined rate.
Implementation Detail: Rather than a literal queue data structure, an efficient implementation uses time. You maintain a
next_free_timevariable representing when the next request can be processed:Python
if request_arrival_time >= next_free_time:
process_immediately()
next_free_time = now() + interval
else:
wait_time = next_free_time - request_arrival_time
next_free_time += interval
sleep(wait_time) # or reject if the queue capacity is exceededBehavior: With a processing rate of 2/sec (0.5s interval), the Leaky Bucket guarantees that exactly one request is handled every 0.5 seconds, effectively smoothing out any spikes. The bucket’s “capacity” here refers to how many requests can be queued before they are rejected, but it never allows for a simultaneous burst of processing.
Practical Comparison:
In most real-world scenarios, the Token Bucket is more practical because it offers better responsiveness by allowing minor bursts. However, the Leaky Bucket is essentially a "simplified queue."
For instance, if an admin triggers 10 heavy report-generation tasks at once, a Leaky Bucket prevents OOM (Out of Memory) by forcing them to be processed sequentially at a safe speed, achieving the benefits of a Queue + Worker setup without the architectural complexity.
Interviewer: How to Configure Rate Limit Parameters?
When an interviewer asks how to set the actual limits, they aren’t looking for a magic number. They want to see a Configuration Strategy:
Identify Dimensions:
Authenticated APIs: Limit by
User IDorAPI Key.Public APIs: Limit by
IP Address. (Note the caveat: multiple users might share one IP, such as a corporate Wi-Fi, and you must handle proxy headers to get the true client IP).
Identify Resource Bottlenecks:
Analyze the capacity of your Database, Redis, or third-party services (SMTP, SMS gateways). Know the connection pool limits and the external provider’s own rate limits.
Data-Driven Decisions: * Don’t guess. Analyze production logs to find P95 and P99 request rates as a baseline.
Set up real-time monitoring to observe 429 (Too Many Requests) error rates and system resource utilization to fine-tune the limits dynamically.
Interviewer: How to implement a Distributed Rate Limiter?
As systems scale, rate limiting data must be stored in a centralized store, typically Redis. The primary challenge here is handling Race Conditions under high concurrency.
The Atomicity Problem: Even though Redis is single-threaded, a rate-limiting check involves multiple steps: GET counter, CHECK if limit exceeded, and INCR counter. If these are sent as separate commands, Redis cannot guarantee they will be executed as one uninterrupted block. Two different API servers could GET the same counter value, both pass the CHECK, and both increment it, leading to a limit violation.
The Solution: Lua Scripts
To ensure Atomicity, you must wrap the logic in a Lua script and send it to Redis. Redis executes the entire script as a single, atomic command. During its execution, no other commands can interfere.
This prevents race conditions entirely and ensures that the “check-and-set” logic is thread-safe across the entire distributed cluster.