
Kubernetes Network 是怎麼運作的?上集
解析 Pod 之間的網路通訊技術

K8S CNI (Container Network Interface) 定義了 K8S 網路通訊需要的 API,但底層 CNI 實作究竟是如何實現 K8S 網路通訊的呢?
首先,我們先回答一個最基礎問題:
K8S 在網路層要解決什麼問題?
K8S cluster 會有多個 worker node,每個 node 有多個 pod,一個 pod 是一個 container 有自己的 network namespace,隔離了網路可視範圍,因此初始時,pod 之間是看不到彼此的,即便這些 pod 都是在同一個 node 裡面。
如何讓相同 Node 之間的 pod 能互相交換封包?
小時候去朋友家玩世紀帝國,即便沒有網路,只要電腦有網卡,透過網線接上交換器,就可在區網看到彼此的電腦連線對戰。
相同概念,可在 kernel 中建立虛擬交換器 (aka linux bridge),紀錄 IP & Mac address 的轉換,並透過 veth pair 將所有 pod 接上虛擬交換器,而 veth pair 類似虛擬網線,接上瞬間,kernel 會為這個 namespace 建立虛擬網路接口,類似虛擬網卡並分配 Mac Address 和綁定你指定的 IP ,這樣所有 pod 可透過 linux bridge 交換封包。

image source: https://linux-blog.anracom.com/2017/11/14/fun-with-veth-devices-linux-bridges-and-vlans-in-unnamed-linux-network-namespaces-iii/
那麼跨 Node 之間的 pod 要怎麼交換封包?
當 destination IP 不在 linux bridge 中,勢必在不同機器上,此時 pod 的 outbound 封包要透過 node 的 root kernel 送出,且 destination IP 不在是 pod IP 而是另一個 node IP,這樣外部 layer 3 網路才知道怎麼轉送封包。
例如 podA -> podB’s IP -> nodeA -> nodeB’s IP -> nodeB -> podB’s IP -> podB
但上面這條路經有兩個問題要克服:
node B 收到 destination IP 是 node IP 時,要怎知道該封包要給哪個 pod?
答案是透過 overlay network 跟 tunneling 技術:
tunneling 技術是封包疊加技術,例如原封包 destination ip 是 podB’s IP,透過 tunneling 疊加一層,讓 destination ip 變成 nodeB’s IP,當 node B 收到後移除疊加資訊,就能護得 pod B’s IP。

image source: https://www.geeksforgeeks.org/computer-networks/vxlan-vs-nvgre-whats-the-difference/
而實際的疊加跟移除是透過 overlay network,例如 VXLAN 在 kernel 中運行一個 UDP service bind 在 4789 port,類似一個虛擬 router (vxlan device),Node A 送封包時,把 dest IP 是 podB’s IP 的 TCP 封包封裝成 dest IP 是 nodeB’s IP 的 UDP 封包,送往 4789 port,VXLAN service 收到後會解析 UDP 獲得給 podB’s IP 的 TCP 封包,而這個 UDP network 是疊加在 TCP network 上的,所以稱為 overlay network。
node A 要怎麼將 podB’s IP 換成 nodeB’s IP?
首先 K8S 需要做到在每個 pod 初始化時分配一個 private IP,且該 IP 跨 Node 之間不能碰撞,因此需要獨立的 control panel server 負責管理所有 node 可用的 CIDR (e.g 10.0.0.0/32 )。
接著一樣透過 overlay network,node A 將 dest IP 是 podB’s IP 的 TCP 封包送給,VXLAN 這個虛擬 router (vxlan device),VXLAN 會透過從 control panel 獲得不同 Node 負責的 CIDR ,將封包封裝成 dest IP 是 nodeB’s IP 的 UPD 封包送出。

image source: https://www.digitaltut.com/vxlan-tutorial/2
有了讓 Pod 之間溝通的能力後,接下來要解決 Pod IP 重啟後會一直改變的問題。
如何用一個固定 private IP 送請求到特定的 Pod?
當 Pod 更新重啟,IP 重分配會改變,對 Client 端非常不方便,因此 K8S 提供 Service Endpoint,建立 Service Endpoint 時,K8S 會分配一個 IP,並透過 label selector 找到要綁定的 pod,將送往該 service IP 的請求 forward 到 pod 中,只要 service 不重建,pod 不斷重啟都不影響 client 用 service IP 送請求到 pod。
而將相同 service IP 請求轉發給不同 pod 的功能,本質上並不是 Pod 之間的網路通訊,而是一個 Layer4 Load Balance,因此傳統 CNI 例如 Flannel 不負責轉發,只負責 Pod 之間的 Layer 3 通訊。
因此 Layer4 Load Balance 是由 kube-proxy 一個 K8S 架構中的核心模組實現的。
kube-proxy 如何將 destination IP 是 service IP 的封包 forward 給 pod 呢?
早期版本是用 iptable,iptable 是使用 kernel netfilter module 的網路封包規則管理工具,netfilter 在 kernel 中負責封包解析 & 連線追蹤,其提供在解析前跟解析後插入 hook 功能,例如 layer 3 解析後,插入一個阻擋特定 ip 的 hook 就能實現防火牆功能,而這就是 iptable 最重要的功能之一。
:原理、应用及Linux 内核实现")
image source : https://arthurchiao.art/blog/conntrack-design-and-implementation-zh/
iptable 可在不同時間點建立不同功能的規則:
PREROUTING:kernel layer 3 解包後,進入 routing 規則前
INPUT:執行完 routing 規則,發現是自己的封包,處理這個封包前
FORWARD:執行完 routing 規則,發現不是自己的,forward 出去給其他人前
OUTPUT:user space process 送封包給 kernel,執行 routing 之前
POSTROUTING :完成 routing decision,確定網路出口介面後,送出封包之前
常見防火牆是在 INPUT 加上特定 IP DROP 規則,可擋 inbound request,在 OUTPUT 加上 DROP 擋 outbound request。
當封包經過 VXLAN 解包獲得 dest service IP 的 TCP 封包時,可建立 PREROUTING 規則,將 service IP 修改成 pod IP 來實現封包轉發,當一個 service IP 背後有多個 pod 時,會建立多條規則,透過設定 probability 實現 load balancing,例如有三個 pod,會建立三個 PREROUTING 規則,由於規則是一條條順序執行的,所以第一條執行成功機率 33%,第二條 50%,第三條 100%,就能在機率上讓請求平均送往三個不同 pod。
修改 dest IP 後進入 routing 送往 bridge 轉發給 pod 或者給 vxlan device 送往其他 node。
除了修改 destination IP 之外,為何還要修改 source IP?
pod 收到 request 後,送出 response 時會需要將 source IP 從 pod IP 還原成 service IP,但是為何?
原因在於 TCP 建立是有狀態的,會透過 (src_ip, src_port, dest_ip, dest_port, protocol) 組成連線 ID,紀錄該連線中封包接收狀況,有沒有遺漏,要不要 retry,client 建立 TCP 時是用 service IP 為 dest_ip,如果 response 的 src_ip 不是 service IP 在 client kernel 中會無法匹配該封包屬於哪個 TPC 連線而被丟棄,因此需要修改 response 的 src_ip。

image source: https://www.napatech.com/what-is-a-flow/
但不是所有 response 的 src_ip 都要改,假設 pod A 往 pod B 建立兩條 TCP connections,src_port 會隨機分配:
conn_1 使用 service IP ,id 為 (src_ip, src_port_1, service_ip, dest_port, protocol)
conn_2 直接用 pod IP,id 為 (src_ip, src_port_2, pod_ip, dest_port, protocol)
那只有 conn_1 的 response src_ip 要從 service_ip 改成 pod_ip,conn_2 則要保留,要做到這件事情,就需要紀錄每個原始 connection 的 id,也就是 netfilter conntrack 功能。
conntrack 可用 connection id 紀錄經過 netfilter 建立的 TCP 連線,以及轉換表,有了 conntrack 可以過濾出 conn_2 沒有轉換過,不需要修改,而 conn_1 有轉換過,需還原 src_ip 為 service IP。
使用 iptable 有什麼缺點?
iptable 主要是防火牆功能,但 K8S service IP 確是 forward + load balancer,因此使用 iptable 有兩個缺點:
效能差:iptable 需要 for loop 所有規則,直到第一個規則命中後才 break,如果 service 很多,pod 很多,效能會很差
load balancer:只能用機率實作,沒有確定,客製化程度低,例如不能用 Round Robin
而 IPVS 是 Linux kernel 透過 netfilter hook 實作的 L4 Load Balancer 模組,安裝 ipvsadm 工具後,可直接往 IPVS 建立 routing table,是一個 hashmap 結構,O(1) 查找效能更好,且支援多種 load balance 策略,例如 Round Robin or Least Connections。

image source: https://www.linkedin.com/pulse/iptables-vs-ipvs-kubernetes-vivek-grover/
有了 IPVS & ipvsadm 之後,仍需要一個 process 去監聽 control panel 的 pod & service 變化通知,有新的 pod 建立需要綁定 service IP,就要透過 ipvsadm 修改 routing table,而這個 process 就是 kube-proxy。
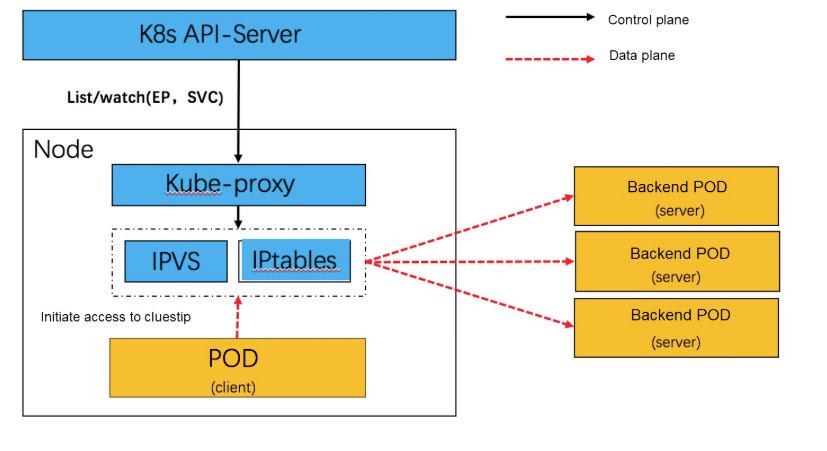
image source : https://www.alibabacloud.com/blog/improving-kubernetes-service-network-performance-with-socket-ebpf_599446
下集預告
使用 IPVS 實現 L4 load balancer 效能已經不錯了,但好還要更好,在之前 cloudflare 文章中提到,ebpf 也可實現 L4 load balancer,下集就來說說,ebpf 的 load balancer 更好在哪裡。
此外,雖然有 L4 load balancer,但是要實現 grpc load balancing 通常需要搭配 service mesh + sidecar,為什麼只有 sidecar 能解決 grpc load balancing,而 ebpf 又怎麼讓 sidecar 效能大幅提升,會一起在下集說明!