
Kubernetes Network 是怎麼運作的?下集
解析 eBPF 高效的秘密

K8S CNI (Container Network Interface) 定義了 K8S 網路通訊需要的 API,上集介紹 CNI 如何實現 Pod 之間的通訊,最後提到傳統 iptables 實現的 L4 load balance 效能較差,可改用 IPVS,但實務上 K8S v1.35 後,在 kube-proxy 中將 IPVS 標記為棄用,為什麼?
回顧,為何 IPVS 會出現?
K8S 中的 L4 load balance 功能可將多個送給相同 service IP 的 TCP 建立請求,送給不同的 pod IP,傳統用法是 iptables。
iptables 是 kernel 中 netfilter module 內建的規則管理模組,netfilter 在封包過濾轉發過程中定義了不同 hook 點, iptable 負責儲存管理這些 hook 的封包規則,例如是否要 drop,allow or forward。
但 iptable 無法客製化 hook callback,而是提供有限的 hook 規則配置,因此用 iptable 實現 L4 load balance 時,會受限於 iptable 功能以及內部實作而影響效能。
好在 netfilter 另外提供 nf_register_net_hook() 能插入客製化的 callback,而 IPVS 就是透過插入客製化 callback 實現高效的 L4 load balance。
例如 iptables 缺點是需要 for loop 多條規則加上機率命中實現 load balance,但 IPVS 作為獨立的 module 不受限 iptables 內部結構,可用 hashmap 實現 O(1) 的 load balance。
但為何要棄用 IPVS?
IPVS 雖然是高效 L4 load balance,但 netfilter 整個模組還有很多功能,例如紀錄 service IP 跟 pod IP 轉換的 NAT & DNAT & conntrack 功能,如果 IPVS 要更完善更高效,就要實現 netfilter 模組其他功能。
這時出現一個開發抉擇,與其花時間完善一個 plugin 定位的工具,讓他有更多功能,不如將原本 netfilter 的 iptables 模組修改成,使用更高效結構管理規則的模組,因此 netables 就誕生了,最後 K8S v1.35 後將 IPVS 標注為 deprecated,改而推薦用 netables。
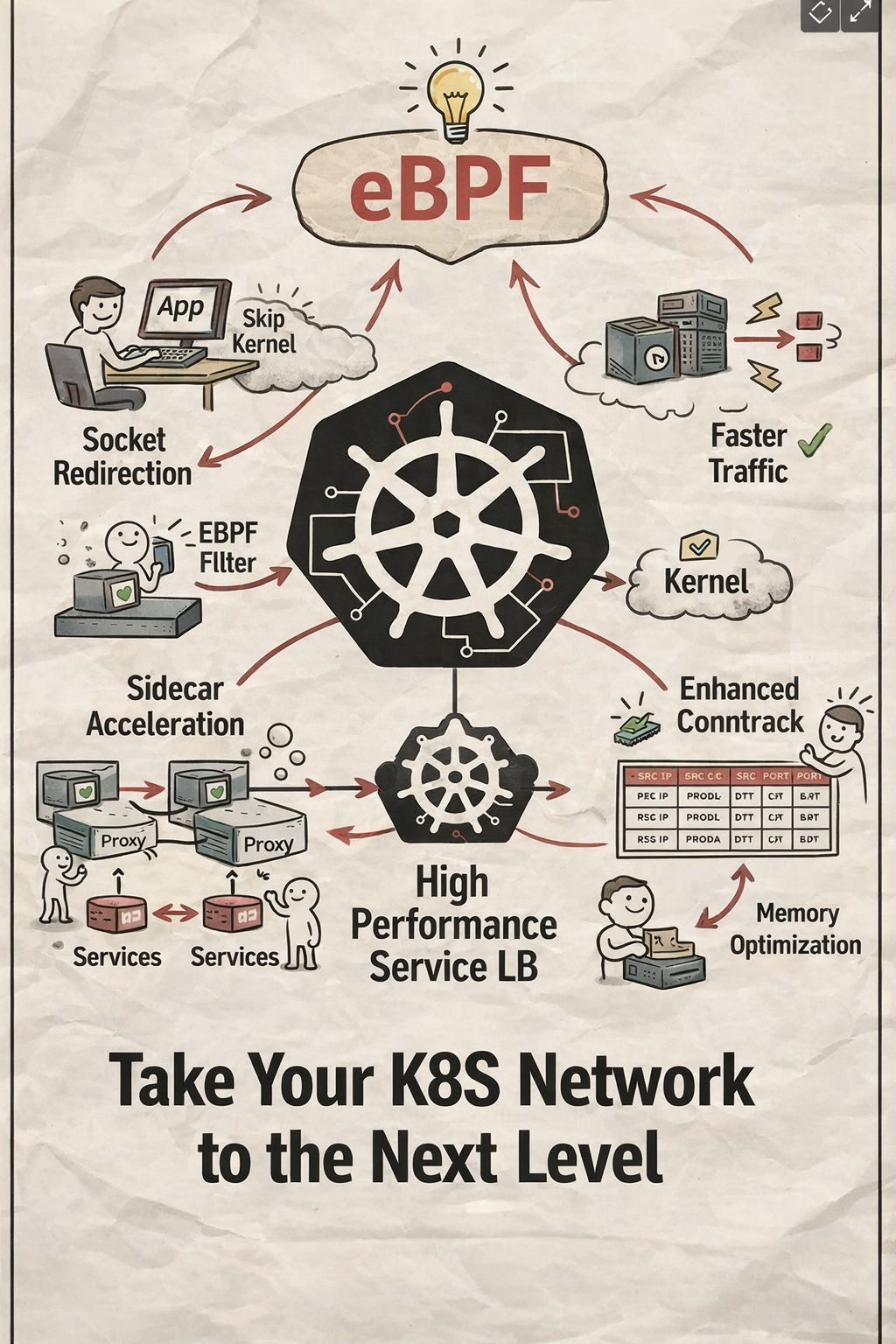
更高效的 CNI 架構,eBPF 技術如何加速 Pod 之間通訊?
早期 K8S Cluster,CNI 只負責 Pod 的 IP 分配跟 Pod 之間通訊,例如 Flannel 跟 kube-proxy 搭配,但新興 CNI (e.g cilium) 採用 eBPF 技術,不只 Pod 之間通訊更快,甚至能替代 kube-proxy L4 Load balance 功能。
傳統 Flannel CNI 技術,Pod 之間通訊會透過 overlap 技術,將 TCP packet 封裝成 UDP packet,節點接收後,UDP packet 會先經過 kernel 的 netfilter 模組 forward 給 vxlan device ,然後 vxlan device 解包後,將 TCP packet 再經過一次 netfilter 模組,找到 veth pair 建立的虛擬網卡,送給 container,因此會經過兩次 netfilter。
eBPF 是可在 kernel 層插入客製 hook 邏輯的技術,但插入點不受限於 netfilter modul,而是 kernel 有暴露的 hook 點都有機會插入。
 - Mostly nerdlessMostly nerdless")
image source : https://mostlynerdless.de/wp-content/uploads/2024/08/network_stack-1.png
因此 eBPF 技術的 CNI,可在 kernel 收到封包,進入 netfilter 模組前,插入一個 hook callback,來繞掉 netfilter 的執行,而 TC (traffic control) 是在 netfilter 前負責流量控制的模組:
TC ingress:管理 inbound packet 的處理速度,有 rate limit 機制,跟對 packet 或 socket 打標籤
TC egress:控制 outbound packet,可做到重新編排,依照 ingress 的標籤決定 priority
若用 eBPF 在 TC Ingress 插入一個 hook,並實現 overlay 解包加封包 forward 的功能,就能避免 netfilter 執行兩次的 CPU 消耗。
例如在 kernel 中,每個封包都是一塊記憶體 (e.g bytes array),而 skb 是 kernel 用來管理封包記憶體的結構,eBPF 可透過修改 skb 的記憶體起始位置,跳過 overlap header實現解包。

image source : http://jared.web.fc2.com/sk_buffer_analysis.pdf
最後轉發可透過 bpf_redirect 這個 BPF helper,bpf_redirect 需接收 ifindex 參數, ifindex 是網卡設備在 kernel process 中的 id,這個 id 會在 veth pair 建立是獲得,可被 CNI control panel 管理,當 eBPF bpf_redirect 轉發封包後,會回傳 TC_ACT_REDIRECT,告訴 TC module 封包被 redirect,不用往下給 netfilter。
![译] 如何基于Cilium 和eBPF 打造可感知微服务的Linux(InfoQ, 2019)](https://substackcdn.com/image/fetch/$s_!MNqF!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F4ca8f294-fab8-4f61-8f7a-402dcb58a1b2_1685x946.png "译] 如何基于Cilium 和eBPF 打造可感知微服务的Linux(InfoQ, 2019)")
image source : https://arthurchiao.art/blog/how-to-make-linux-microservice-aware-with-cilium-zh/
繞過 netfilter 後,kube-proxy 就用不到了,怎麼實現 service endpoint ?
kube-proxy 是透過 netfilter 實現 service endpoint 的 Layer 4 Load balance,一旦 eBPF CNI 繞過 netfilter,就無法用 kube-proxy,因此要另外開發 Layer 4 Load balance。
eBPF 實現 Layer 4 Load balance 的好處之一是 conntrack 可自行管理,由於 TCP 連線是有狀態的,連線內封包須送往同一個 pod IP,但 client 只看到 service IP,因此 kube-proxy 透過 netfilter conntrack 機制,儲存 service IP 跟 pod IP 的轉換,而 netfilter 的 conntrack 不只是 IP 轉換,還用於實現有狀態的防火牆機制,例如不 DROP 連線建立後的封包,所以 conntrack 還會記錄額外資訊。
但單純 Load balance 其實可紀錄更少的資料,且 eBPF 自行管理 conntrack 也不會受限 kernel nf_conntrack_max 參數限制,且能優化 hashmap 的儲存結構,更高效地乘載大量 TCP 連線。
什麼是 service mesh?非 eBPF service mesh 有什麼效能問題?
eBPF 雖然實現 Layer4 Load Balance,但該 Load balance 並不能用在 gRPC 上。
K8S 內部服務溝通,常見的 Layer7 協定是 gRPC,gRPC 用 TCP 長連線,一旦連線建立,所有 gRPC 請求都會送往同個 backend server。
實現 gRPC load balance 常見 solution 是 service mesh,每個 pod 搭配獨立 proxy 稱為 sidecar,proxy 彼此之間建立 gRPC 連線,形成網狀關係,server to server 溝通時,client 請求透過 proxy 送出,此時 client proxy 可決定要送往哪個 server proxy 實現 load balance。

image source : https://learn.microsoft.com/zh-tw/dotnet/architecture/cloud-native/service-mesh-communication-infrastructure
因此 sidecard proxy 要接收 pod 的 inbound & outbound request,而非 eBPF 的 service mesh 是透過 iptables 修改 netfilter 路由規則,把所有 outbound address 都修改成 proxy address,讓 pod 所有請求都透過 side car proxy 送出。
service mesh 沒法用 iptable 的 FORWARD rule 直接轉發,因為 FORWARD 是用在不同網路接口,但 side car 跟 server 是同一個網路接口,所以轉發要透過修改 dest address。
修改 dest address 後,還要再經過 kernel 的 netfilter 模組一次,封包才會到 proxy,等於說 server to server 透過 side car proxy 溝通時,會有兩次 netfilter 的 datapath:
1. 第一次 netfilter 修改 dest address 到 proxy
2. 第二次 netfilter 依照新的 dest address forward 封包給 proxy
兩次 netfilter 代表更多 CPU 消耗,而 eBPF 能解決該問題。
eBPF 如何實現更高效的 service mesh?
首先 eBPF 可在 server 對外建立 tcp 連線時,攔截建立請求,將 dest address 修改成 proxy address,server 看似對外建立了 tcp 連線,實際是與 side car proxy 建立連線,此舉避免了透過 netfilter 去轉發到 proxy。
連線建立後,避免 server 往 proxy 送封包時要經過 netfilter,eBPF 會用 Sockmap 結構,將兩個不同 process (server & proxy) 在 kernel 中 socket 物件做關聯,當 server 送封包出去時,會被 eBPF hook 攔截,發現 dest socket 在 Sockmap 有關聯,可直接往對應的 socket 送,不需經過 netfilter。
原本沒 eBPF 的 service mesh ,side car 要攔截 outbound request 需經過兩次 netfilter,有了 eBPF 是 0 次,因此效能更好,甚至 eBPF 下的 service mesh 能更好地支援 per node 的 proxy 架構。

image source : https://isovalent.com/blog/post/2021-12-08-ebpf-servicemesh/