
Spark 如何打敗 Hadoop Map Reduce?
解析分散式運算架構 - DAG、shuffle 到 fault tolerance

AI 時代,data processing 變得重要,feature pipeline、資料清洗、data ingest 到 data warehouse,或是在 lakehouse 上跑大規模 batch query,本質上都在處理同一件事:大量資料要被穩定、快速轉換成我們需要的樣子。
在這個領域裡,Spark 幾乎是最重要的基建之一,但 Spark 到底是什麼?
為什麼不是寫一支 Python script 就好?為什麼有了 Hadoop MapReduce 和 Hive,後來還需要 Spark?
Spark 是什麼?為什麼 data pipeline 需要它?
當資料不多時,從 A database 搬到 B database,或做資料轉換,一支 Python script 就夠了,但資料變大後或資料新增速度太快時,一台機器往往不夠。
例如 orders table 的 insert rate 很高,要把 binlog real-time ingest 到 data warehouse。單一 Python process 會追不上寫入速度,會因為 memory、CPU、I/O 都被單機限制住,無法穩定處理。
這時候需要分散式運算。
分散式運算核心是:把資料切成 partitions,分給多台機器平行處理,像是 Kafka partition、database shard、data lake partition,都是把資料分散到不同地方。。
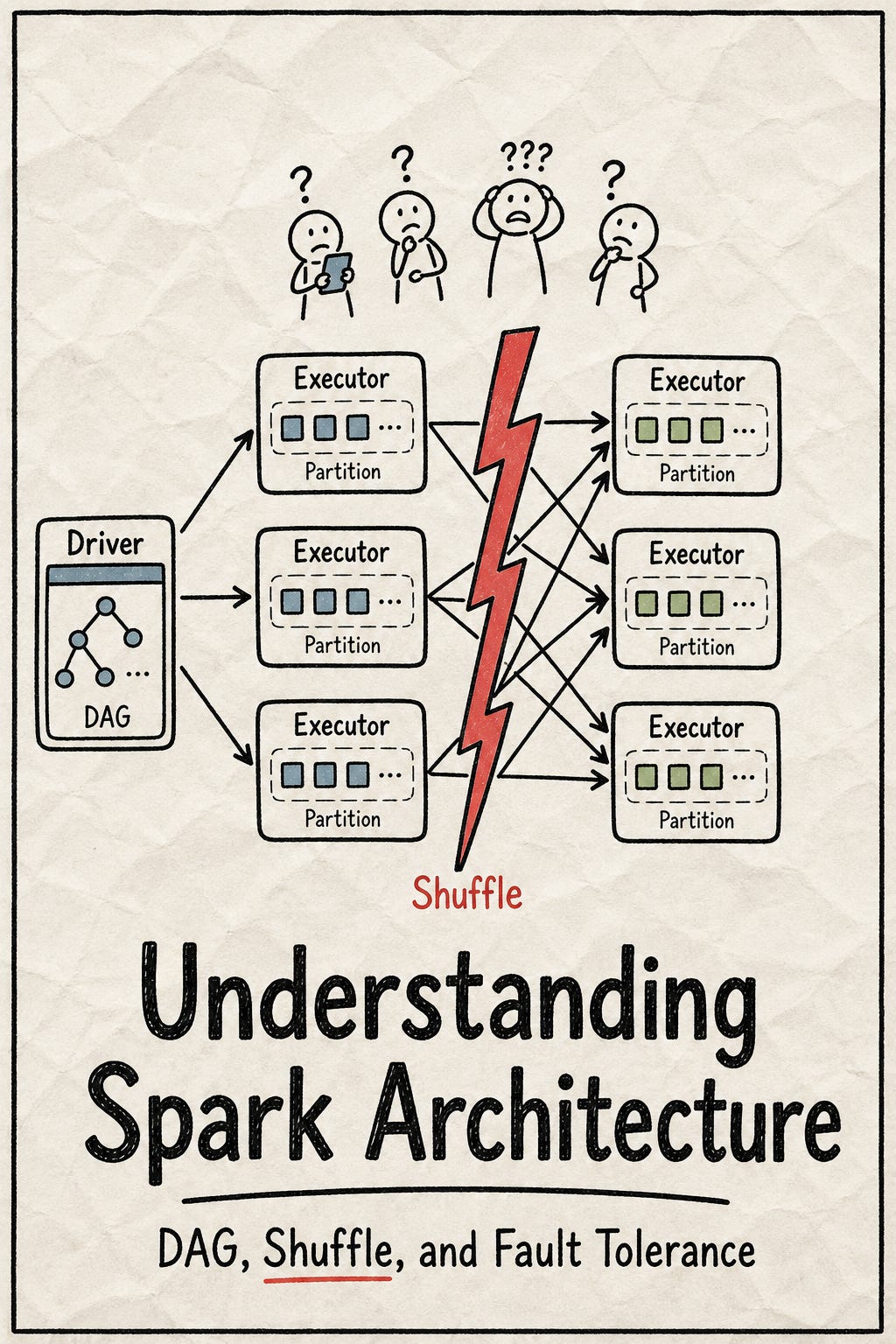
因此 Spark 不只是「跑 pipeline 的工具」而是分散式運算 runtime,它真正處理的是:當資料計算跨越多台機器時,runtime 要如何安排計算、交換資料、追蹤依賴,並在機器失敗時恢復。
為什麼單純把資料分給多台機器還不夠?
假設執行:
select uid, sum(amount)
from orders
group by uid;
orders 很大,所以資料被切成多個 partitions,分散在不同 executor (i.e machines) 上。
第一步,每台 executor 先處理自己 partition 裡的 records,算出局部結果:
| executor | partial result |
| --- | --- |
| 1 | `[uid=1, amount=100]`, `[uid=2, amount=200]`, `[uid=3, amount=300]` |
| 2 | `[uid=1, amount=50]`, `[uid=2, amount=250]`, `[uid=3, amount=40]`, `[uid=5, amount=80]` |但這不是最終答案,要把不同 executor 的局部結果依照 uid 聚合獲得 global sum。
因此分散式運算 runtime 分發資料後,還需要安排資料交換,這個「依照 key 重新分配資料」的過程,就是 shuffle。
例如:
uid=1 的資料同時出現在 executor 1 和 executor 2,要把所有 uid=1 的 partial results 送到同一個 reducer。
shuffle 後,資料會變成:
| reducer | final result |
| --- | --- |
| 1 | `[uid=1, amount=150]` |
| 2 | `[uid=2, amount=450]` |
| 3 | `[uid=3, amount=340]` |
| 4 | `[uid=5, amount=80]` |而這也是 MapReduce 的基本模型:
Map:每台機器先處理自己的資料。
Shuffle:依照 key 把相關資料送到同一個 reducer。
Reduce:每個 reducer 對自己負責的 key 做聚合。
Hadoop MapReduce 作為早期知名的分散式運算 runtime 能讓工程師把一段分散式計算拆成 map -> shuffle -> reduce。
而實現資料交換的關鍵在於 runtime 要知道資料的依賴關係,哪些 reduce 的 input 來自於哪些 map 的 output,因此 runtime 在執行計算時,會將計算過程變成 Directed Acyclic Graph (DAG):
groupBy -> sum -> shuffle -> sum
但裸 MapReduce 問題是,開發者要自己實作 map object 和 reduce object,當 computation 變複雜,例如:
filter -> join -> aggregate -> sort -> another aggregate
就會有多個 MapReduce jobs 跟實作多個 map/reduce object,且 job 之間的依賴與中間結果銜接,需要上層系統或開發者管理。
因此 Hive 出現了:不用直接寫 map/reduce object,而是可寫 SQL。
Hive 會把 SQL 解析成 query plan,優化查詢,再編譯成多個 MapReduce jobs。
例如 Hive 編譯下面 query 時,會優化實際 map reduce 的 group by 邏輯:
select campaign_id, count(*)
from clicks
group by campaign_id;最暴力的做法是 mapper 把每筆資料都 shuffle 給 reducer:
(a, 1), (a, 1), (a, 1), (b, 1), (b, 1)
shuffle 後:
(a, [1, 1, 1]), (b, [1, 1])
但 count 有數學交換性與結合性,所以 mapper 可以先做 local partial aggregation:
(a, 3), (b, 2)
再把 partial count shuffle 給 reducer。
這樣可以減少 shuffle data 傳輸量。
有了 Hadoop Map Reduce + Hive,為何還需要 Spark?
Hadoop Map Reduce runtime + Hive 有一些限制:
第一個限制,DAG 的 boundary:
Hadoop Map Reduce runtime 一次只管理一段 map -> shuffle -> reduce,意味著 DAG 裡只記錄一個 map reduce job 的計算過程,如果有多個 map reduce job,會有多個不相連的 DAG:
map1 => shuffle1 => reduce1 => DAG1
map2 => shuffle2 => reduce2 => DAG2
當 map2 資料來自於 reduce1,未避免 map2 執行一半 crash 重啟,需要把 reduce1 資料持久化,因為 runtime 從 DAG2 的角度來看,input 資料來自於某個 partition 而不是透過計算獲得的。
因此 Hadoop Map Reduce runtime 每執行完一個 job 會把結果寫進 HDFS (分散式檔案系統) 中。
例如,filter -> join -> aggregate -> sort -> another aggregate,在傳統 Hive on MapReduce 裡,可能會變成:
Job1: filter
寫回 HDFS
Job2: join
寫回 HDFS
Job3: aggregate
寫回 HDFS
Job4: sort
寫回 HDFS
Job5: aggregate儲存中間結果會讓整個 pipeline 更穩定,但 HDFS 儲存成本不低,會有額外的 disk I/O & network I/O。
第二個限制是 optimization 的時機:
Hive 在執行前產生 query plan。它可以根據語法、規則、statistics 做優化,也就是說 optimization 是在執行前完成,無法根據執行中的資料真實情況 (e.g shuffle size、partition size、data skew) 重新調整後面的 strategy。
因此 spark 的挑戰變成:
如何避免每一步都把中間結果寫回 HDFS,同時保證 pipeline 可靠?
如何在執行時根據真實資料量調整 plan?
Spark 怎麼解決 Hadoop Map Reduce + Hive 的缺點?
首先 Spark 的核心想法是保留完整的 computation lineage (某個資料結果是怎麼從源頭資料一步一步算出來的)。
例如:
map1 -> shuffle1 -> reduce1 -> map2 -> shuffle2 -> reduce2
在 Spark 裡,這不是多個斷開的 MapReduce jobs,而是一條完整的 dependency graph。Spark runtime 知道下游資料依賴哪些上游 transformation,也知道哪裡需要 shuffle,哪裡可以直接 pipeline。
因此,Spark 不用把中間結果寫回 HDFS,中間結果可留在 executor memory 或 local disk。若某個 executor 掛掉,memory 裡的資料遺失,Spark 仍可依照 lineage 從上游 partition 重新計算。
也就是說 Spark 的 fault tolerance 不是靠每一步都 materialize 到可靠儲存,而是靠「知道怎麼重算」。
第二,Spark Runtime 原生支援語法解析編譯,例如 Spark SQL 把 optimization 和 runtime execution 緊密地結合實現 Adaptive Query Execution。
例如執行:
select SUM(orders.amount), products.name from orders
join products on orders.pid = products.id group by products.name;初始 Spark 估計 join 的 products 資料量很大,所以用 Sort Merge Join,避免建立太大的 hash table (OOM risk)。
但實際執行到 shuffle 後,Spark 發現某一側資料比預期小很多,此時 AQE 可把後續 join strategy 改成 Broadcast Hash Join,或合併過小的 shuffle partitions,讓執行更貼近真實資料分布。
簡單來說,Spark runtime 具備解析編譯不同查詢語言以及建立完整 computation lineage DAG 的能力。
而除了依照真實資料做 query optimization,DAG 的內容也會影響 Spark runtime 執行的策略。
Spark DAG 如何影響查詢優化?
一個分散式查詢的效能,很大程度取決於 shuffle boundary。
shuffle 不只是「有網路傳輸」而已。它通常包含:
records 依照 key、range 或 hash 被重新分發
map side 寫 shuffle files
reduce side 從多個 map outputs fetch 自己需要的資料
若資料傾斜,某些 reduce tasks 可能變成長尾瓶頸
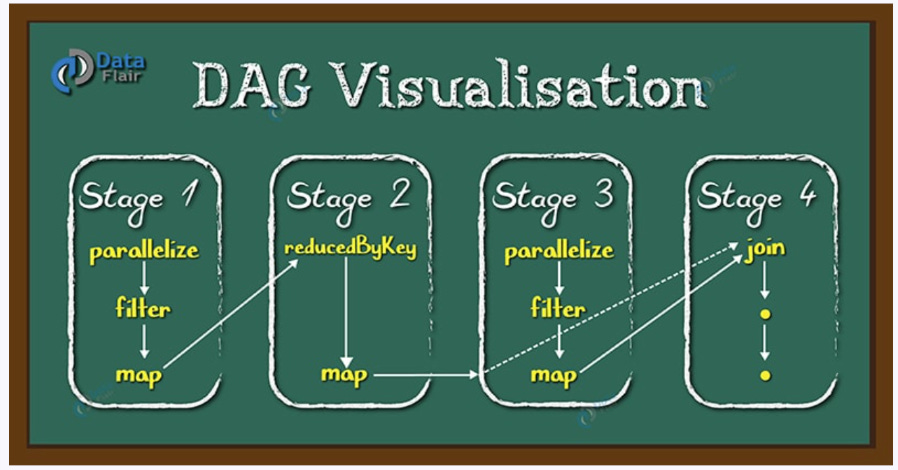
因此 Spark DAG 不只描述「先做什麼、後做什麼」更重要的是標記哪些 dependency 會形成 shuffle boundary。
在 Spark DAG 中,每個 transformation step 的 output/input data 稱作 Resilient Distributed Dataset (RDD),一個 DAG 結構中:
Node 是 RDD
Edge 是 dependency
dependency 又可以分成 narrow dependency 和 wide dependency。
Narrow dependency 指 parent RDD 不用依照 key、range 或 hash 重新分發,資料流向是固定的,通常可以在同一個 stage 內 pipeline。
例如 `filter、`map`、`flatMap`。
Wide dependency 指的是 parent RDD 需要被重新分配到多個 child RDD,會觸發 shuffle,也會形成新的 stage boundary。
而在 Spark DAG 會用 stage 明確表明哪些 transformation step 可在 pipeline 完成,什麼時候會觸發 shuffle 切出新 stage,通常在相同 stage 的 transformation step 可並行處理不同 partition,但跨 stage 時,下游 stage 必須等上游 stage 全部完成後才能開始:
回到這個 query:
select uid, sum(amount * 2) as total
from orders
where status = ‘SUCCESS’
group by uid;概念上可以理解成:
RDD1: orders
filter status = SUCCESS
RDD2: successful orders
map to `(uid, amount * 2)`
RDD3: `(uid, value)`
reduceByKey sum
shuffle boundary
RDD4: `(uid, total)``RDD1 -> RDD2 -> RDD3` 是 narrow dependency,filter 和 map 可在同一個 task 裡 pipeline 執行。不同 partitions 可分散到不同 executors 平行處理。
`RDD3 -> RDD4` 是 wide dependency,因為相同 `uid` 的 records 分散在不同 partitions,Spark 必須依照 `uid` 重新分發資料,讓同一個 key 的資料聚在一起做 sum。
這就是為什麼 shuffle 是 Spark 效能分析的核心,簡單的分類:
Narrow Dependency: filter / map / flatMap / union
Wide Dependency: aggregation + group by or reduce by
除了 Aggregation + Group By 之外還有哪些 Query 會觸發 Shuffle?
`GROUP BY` 是最直覺的 shuffle 例子,但不是唯一,另一個常見例子是 join。
假設:
select *
from orders o
join users u
on o.uid = u.uid;若 `users` 和 `orders` 分散在不同 partitions,就可能出現:
`user uid=1` 在 executor A。
`order uid=1` 在 executor B。
executor A 找不到對應 order。executor B 找不到對應 user。
因此 Spark 必須把 join key 相同的 records 放到同一個 partition,才能正確 join,就需要 shuffle。
但 join 也有優化機制,若其中一張表很小,例如 `users` table 很小,Spark 可把整張小表 broadcast 到所有 executors,讓每個 executor 都能把自己的 orders partition 和 users table join 起來,不需要把 orders 依照 `uid` shuffle。
也就是 Broadcast Join Optimization。
另一個例子是 global `ORDER BY`。
select *
from orders
order by amount desc;若資料是按照 timestamp partition,但要依照 `amount` 做全域排序,Spark 不能讓每台 executor 各排各的。因為 executor A 排出的第一名,不一定比 executor B 排出的第一名大,也不可能全部放到一個 executor 排序。
因此全域排序需要重新定義 partition range。
Spark 可先 sampling 看 `amount` 的分布,決定 range boundaries,例如:
0 到 50
50 到 100
100 到 200
接著依照 range 把 records shuffle 到不同 partitions,讓每個 partition 負責一段有序範圍。
這樣就不需要把所有資料塞到一台 executor,仍可產生 global ordering。
因此可用一個規則判斷 query 是否可能觸發 shuffle:
只要 query 需要改變資料分布,讓相同 key、join key、或排序 range 的 records 聚在一起,就很可能要 shuffle。
Spark Runtime 實際怎麼管理 executor node?
當 Spark runtime 建立起 DAG,完成 query optimization 跟切分 stage 後,下一步是把這些 computation 跑起來。
一個 Spark application 通常由一個 driver 和多個 executors 組成。
Driver 是控制中心。它負責解析 user program,建立 DAG,切 stages,產生 tasks,並追蹤 task 狀態。
Executor 是執行單位。它負責接收 driver 派發的 tasks,執行 computation,存放 cache / shuffle data,並回報執行狀態。
Driver 裡有兩個核心 scheduler:
DAGScheduler 負責看 dependency graph,決定 stage 如何切分。遇到 shuffle dependency,就會切出新的 stage。
TaskScheduler 負責把每個 stage 裡的 tasks 分配給 executors,並考慮 data locality、executor 狀態、task retry 等問題。
Spark runtime 只管理 computation 和 tasks 分配,不管理 executors 運行的節點狀況,因此需要外部 cluster manager,例如 Kubernetes、YARN 或 Standalone cluster。
Cluster manager 負責管 node 資源:哪些 node 可以啟動 executor、executor 有多少 CPU / memory、node 掛掉後資源如何回收。
當啟動一個 Spark application 時:
1. cluster manager 會幫 Spark 配置 executor resources
2. 接著 driver 透過 RPC 把 serialized task 發給 executor
3. executor 執行完後,把 task status、metrics、shuffle output metadata 回報給 driver
一個 Spark application 裡可有多個 jobs。
job 通常由 action (i.e pipeline 最後的output行為) 觸發,例如 `collect`、`count`、`write`。
例如:
val ordersDF = spark.read.parquet(”/orders”)
ordersDF.filter($”status” === “SUCCESS”).writeTo(...)
ordersDF.filter($”status” === “FAIL”).writeTo(...)這裡兩個 writes 分別寫到不同地方,會形成兩個 jobs,每個 job 有自己的 DAG、stages、tasks 和執行狀態。
再往下拆:
job 由多個 stages 組成。
stage 由多個 tasks 組成。
task 通常對應某個 partition 的 computation。
也就是說 task 是 Spark 中最基礎的運算單位,那如果 task 執行失敗怎麼辦?
Executor task 執行失敗會怎樣?Driver 如何實現 Fault Toleration?
分散式系統一定會遇到 executor 掛掉、task 失敗、GC pause、network timeout。
Spark 的基本策略是:driver 負責 task attempt retry,executor 回報 task 狀態。
Driver memory 裡保存 DAG、stage、task 狀態,以及 shuffle map output 等 metadata,所以 Driver 知道如何 retry task,但是 Driver 有時會誤判 retry 時機。
例如 executor 因為 OOM、GC pause 或 CPU 過載,導致 heartbeat timeout。Driver 可能判定 task failed,並在另一個 executor 啟動新的 task attempt。
但舊的 task attempt 不一定真的停止。它可能只是暫時沒有回應,後來又繼續跑完。
此時就可能出現:
old task attempt 還在寫 output。
new task attempt 也在寫 output。
兩個 attempts 都代表同一個 logical task。
假設這兩個 task 的 output 是 shuffle map output file,此時會導致 reduce task 跟上游 fetch shuffle data 的時候,拿到兩份相同資料,reduce 結果出錯。
因此 Spark Driver 有 attempt-based output isolation 機制,每個 task attempt 寫到自己的 output location 時 output file 還不可見,executor 會向 driver 送出 commit,相同計算內容的 task 共用一個 id,driver 只接受其中一個 successful commit,executor 確認 commit 成功後才把 output file 變成可見。
但這只保護 Spark runtime 能管理的 output file isolation。
若 task 直接寫外部 DB、呼叫外部 API,兩個 task 會有 double write,即便是成功 retry 沒有兩個 task,重新寫入也可能把某批資料重寫兩次。
這時候需要 external sink 自己提供 atomicity。
以 Iceberg 為例,executor 寫資料到 Iceberg Table 時資料是放在不可見的 parquet file 裡,當 task 完成要 commit 時,可透過 Driver 收集所有並行處理 task 的完成狀態並過濾重複的 task,一次發送 Iceberg commit 修改 table metadata 建立新的 snapshot,除了確保並行寫入的資料是原子性之外,也能避免重複 task 的 files 被 commit。
這類設計本質是:資料寫入可先發生,但真正讓資料「可見」的 commit 必須是 atomic 的。
最後還有更外層的失敗:driver 掛掉。
Driver 掛掉時,整個 Spark application 通常就失敗了,通常 Spark 會搭配 Airflow 這類 workflow orchestrator 管理多個 Spark applications 的執行順序、狀態和 retry。
但 Airflow retry 是 application 層級的 retry。
如果 Spark application crash,Airflow 可能重跑整個 application。若遇到 network partition、timeout 誤判,甚至可能出現 new application 和 old application 重疊執行。
這已經不是單一 Spark driver 的 task attempt isolation 能處理的範圍。
因此在 production data pipeline 裡,sink 端通常要有 idempotency key 或 transactional write。
常見做法是使用資料來源的唯一識別資訊作為 deduplication key,例如 Kafka 的 `(topic, partition, offset)`,或業務層的 `order_id`、`transaction_id`,再搭配 upsert / merge 避免重複寫入。
所以 Spark 的 fault tolerance 可分成三層:
Spark runtime 內部:靠 lineage、task retry、attempt isolation 恢復 computation。
Table format / sink:靠 atomic commit、transaction、idempotency 處理 external side effect。
Workflow orchestrator:靠 application-level retry 管理整體 pipeline,但也可能引入跨 application 的重複執行。
Spark 解決的是分散式資料計算 runtime 的問題,它能讓 computation 在 executor 失敗時恢復,也能避免內部 output 被多個 attempts 污染,但當資料離開 Spark runtime,寫入外部系統,正確性就不再是 Spark 單獨能保證的,這也是設計 production data pipeline 時,必須同時理解 Spark、sink table format,以及 orchestrator 的原因。