
如何打造高效 TCP Server 下集 - io_uring:為什麼 epoll 還不夠快?
從 syscall 開銷到 shared memory queue,理解 Linux I/O 的下一個演進

上集提到,Nginx, Redis & Rust tokio 都用 non-blocking I/O 結合 epoll 開發高效的 tcp server (e.g cache server or http server),但 epoll 有其缺點,當 epoll_wait 回傳可讀寫的連線時,讀寫資料仍要額外呼叫 read or write system call,連線多或讀寫頻繁時,這些 system call 在 user space 與 kernel space 之間切換的時間會顯著影響效能。
而 io_uring 就是解決 epoll 這個問題的另一個 kernel 機制,但不執行 read & write system call 要如何讀寫資料?
不執行 read & write system call 要如何讀寫資料?
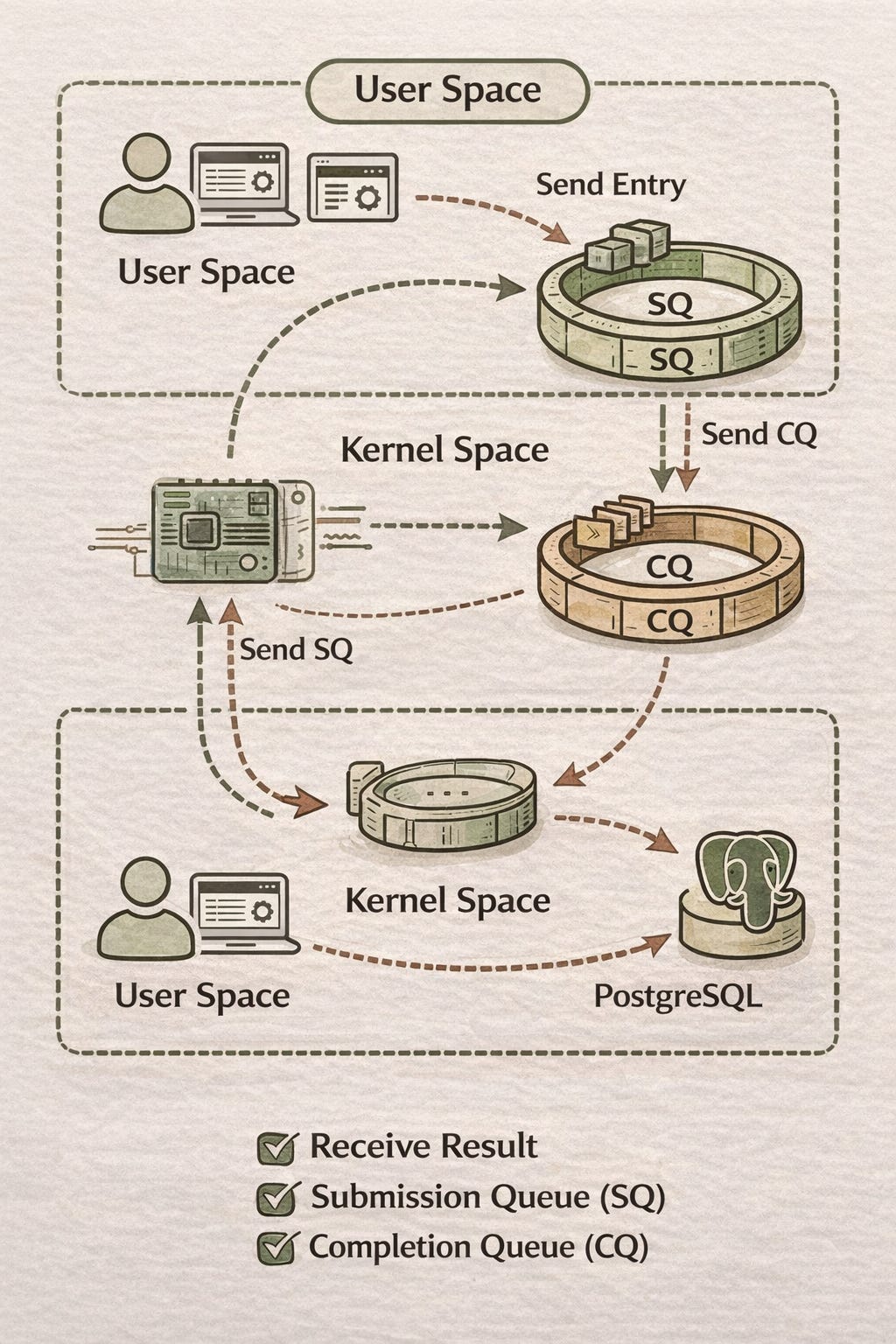
使用 io_uring 時,kernel 會建立兩個 queue:
Submission Queue (SQ) : user space process 將 I/O 操作 (e.g read, write) 請求放進該 queue 由 kernel process 消費
Completion Queue (CQ):kernel process 將 I/O 完成通知放入該 queue 由 user space process 消費

因此即便是 blocking I/O 用 io_uring 讀寫仍是非同步的,讀寫操作會被封裝成 entry 放進 SQ 中,透過消費 CQ entry 拿到讀寫結果,該 entry 結構有以下主要 field :
fd (file descriptor) : I/O object (e.g tpc 連線) 在 kernel 中的 id
opcode : 不同 entry 類型的 enum (e.g read, write or accept)
data pointer : kernel 讀寫資料的記憶體指標,通常會在 user space 初始化 bytes array 並傳該陣列指標
user_data : 該 entry 的識別號
user space process 從 CQ 收到一個 read 完成的 entry 時,需知道去哪個 bytes array 讀資料,因此 CQ entry 中的 user_data 會跟 SQ entry 匹配,能從 user_data 識別號中找到對應的 bytes array,例如把 bytes array 的指標變成 int 放入 user_data :
# 建立 SQE (SQ entry)
struct request *req = malloc(sizeof(*req));
sqe->opcode = IORING_OP_READ;
sqe->fd = req->fd;
sqe->addr = (uint64_t)req->buf;
sqe->user_data = (uint64_t)req;
# 收到 CQE (CQ entry),直接用 user_data 還原 request bytes array 資料
struct request *req = (struct request *)cqe->user_data; 往 SQ & CQ 送 entry 不用 system call 嗎?
雖然 SQ & CQ 是 kernel 裡的物件,但 kernel 透過 mmap system call 將 kernel 的記憶體物件與 user space 的記憶體物件建立關聯,要簡單說明 mmap 技術,首先要提到 virtual memory space 概念:
virtual memory space
每個 user space process 會有各自的 page table 紀錄可存取的記憶體位置,例如 0x000 ~ 0x3FF 代表 1KB,但 page table 記憶體位置不是實體記憶體位置,kernel 會額外透過 mapping 機制,將 page table 的虛擬記憶體位置映射成實體記憶體位置,也就是 Virtual Memory Mapping 技術。

Page Fault & mmap 技術
使用 Virtual Memory 好處是,當 process 執行 malloc(1G) 時,不用馬上給 1G 的 RAM,而是先在 page table 紀錄 0x00000000 ~ 0x3FFFFFFF 範圍都可存取,當 CPU 讀取 virtual memory 的記憶體位置,發現沒有對應的實體記憶體時會觸發 page fault,隨後依照實際用到的大小 (最小單位為 4Kb ) 去向實體記憶體拿資源並建立關聯,相當於 lazy load 技術。
而 mmap 技術在 page fault 時可從指定的實體記憶體讀資料並建立關聯,例如將 process 的 virtual memory space 0x000 ~ 0x3FF 與 kernel 記憶體中 io_uring 的 queue 建立關聯,CPU 讀取 0x000 ~ 0x3FF 觸發 page fault 會直接讀 kernel io_uring queue 的實體記憶體位置,而不是隨機分配空白的實體記憶體,因此該 process 可直接存取到 kernel io_uring 的 queue,不需透過 system call 就能往 queue 送 entry 或讀 entry。
使用 queue 不會有額外的效能消耗嗎?
使用 double linked list 結構的 queue 同時 push & pop 需要上鎖,而 io_uring 使用 ring buffer 透過固定大小陣列加兩個 atomic value 的讀寫 index 實現無鎖的 push & pop :

範例程式:
use std::sync::atomic::{AtomicU64, Ordering};
const SIZE: usize = 8; // 必須是 2 的冪
struct RingBuffer {
buf: [i64; SIZE],
head: AtomicU64, // consumer 寫
tail: AtomicU64, // producer 寫
}
impl RingBuffer {
fn new() -> Self {
RingBuffer {
buf: [0; SIZE],
head: AtomicU64::new(0),
tail: AtomicU64::new(0),
}
}
// Producer 端
fn push(&mut self, val: i64) -> bool {
let tail = self.tail.load(Ordering::Acquire);
let head = self.head.load(Ordering::Acquire);
if tail - head == SIZE as u64 {
return false; // 滿了
}
self.buf[(tail & (SIZE as u64 - 1)) as usize] = val;
self.tail.store(tail + 1, Ordering::Release);
true
}
// Consumer 端
fn pop(&mut self) -> Option<i64> {
let head = self.head.load(Ordering::Acquire);
let tail = self.tail.load(Ordering::Acquire);
if head == tail {
return None; // 空的
}
let val = self.buf[(head & (SIZE as u64 - 1)) as usize];
self.head.store(head + 1, Ordering::Release);
Some(val)
}
}且陣列是連續記憶體空間,對於 CPU 來說能透過一次 cache 存取拿到完整陣列資料,相反地 linked list 節點可能分散在不連續記憶體空間,CPU 可能會有多次 cache 存取。
除了 queue 優化,io_uring 還有哪些效能優化?
雖然沒有 read & write system call ,但 io_uring 仍需要其他 I/O system call,例如提交完所有請求到 SQ 後,需要執行 io_uring_enter system call 告知 kernel 可從 queue 中處理任務,該 system call 會 blocking 直到 CQ 有 entry,不過 system call 仍比 epoll 少:
epoll : epoll_wait 等事件以及 read or write system call
io_uring : io_uring_enter trigger kernel 並等待 CQ entry
SQPOLL 模式實現 zero I/O system call :
若想實現 zero I/O system call,io_uring 支援 SQPOLL 模式,kernel 會用額外 kernel thread 不斷 polling SQ,而 user space process 無需執行 io_uring_enter 只需要不斷 polling CQ 即可,缺點是 CQ 若沒資料該 process 會有許多無效拉取,因此 SQPOLL 適用在請求密集且低延遲的場景中。
IOPOLL 模式優化硬體中斷:
第二個優化是關於硬體中斷,io_uring 一樣透過硬體中斷觸發後,kernel 將讀寫結果放入 CQ 中,但硬體中斷不是毫無成本,CPU 收到中斷指令後,要先執行中斷指令內容,除了停止當前指令外,還會把在指令 pipeline 中的後續指令都移除,中斷處理完後,會回到被打斷的指令位址,解碼後續指令放回 pipeline。
若瞬間收到大量中斷,CPU 反覆清空 pipeline 過程是很消耗的,因此 kernel 使用 NAPI (New API for network packet processing) 技術處理 network 封包的中斷指令,收到第一個中斷後,會切換成 polling 模式,將網卡裡封包都讀出來一次處理,避免瞬間大量封包觸發一堆中斷。
但 NAPI 主要用於網路封包,若將 io_uring 用在 File I/O (e.g 資料庫) 瞬間大量讀取仍會觸發一堆中斷,因此 io_uring 提供 IO_POLL 模式,完全不透過中斷而是不斷 polling 硬體資料。
io_uring 的實際應用:PostgreSQL 18
資料庫系統會對檔案有頻繁的讀寫 I/O,因此 PostgreSQL 在 18 版本對 File I/O 引入 async IO 機制,該機制有兩個模式 worker (default) & io_uring:
worker:將 read() or write() 指令透過 queue 交由 PG 的另一個 process 處理,read heavy query 效能提升約 1.5 倍。
io_uring:將 read() or write() 指令改成 io_uring 方式處理,read heavy query 效能提升約 2.7 倍。
有此可見 io_uring 效能提升最好,不過由於 io_uring 是異步讀寫,PG 提醒用 io_uring 會導致 explain analyze 對於 I/O 處理時間變得不精準。
ref: https://pganalyze.com/blog/postgres-18-async-io

epoll vs io_uring benchmark - monoio vs tokio
如上集所說,Rust 有 Future 抽象化 async 操作,因此可以替換不同的底層 runtime,實際代碼幾乎不用修改,例如 monoio 是用 io_uring 開發的 async runtime,用 monoio 開發的 TCP echo server 與 tokio 程式幾乎一樣:
use monoio::{
io::{AsyncReadRent, AsyncWriteRentExt},
net::{TcpListener, TcpStream},
};
#[monoio::main(driver = "fusion")]
async fn main() {
// tracing_subscriber::fmt().with_max_level(tracing::Level::TRACE).init();
let listener = TcpListener::bind("127.0.0.1:50002").unwrap();
println!("listening");
loop {
let incoming = listener.accept().await;
match incoming {
Ok((stream, addr)) => {
println!("accepted a connection from {addr}");
monoio::spawn(echo(stream));
}
Err(e) => {
println!("accepted connection failed: {e}");
return;
}
}
}
}
async fn echo(mut stream: TcpStream) -> std::io::Result<()> {
let mut buf: Vec<u8> = Vec::with_capacity(8 * 1024);
let mut res;
loop {
// read
(res, buf) = stream.read(buf).await;
if res? == 0 {
return Ok(());
}
// write all
(res, buf) = stream.write_all(buf).await;
res?;
// clear
buf.clear();
}
}為了測試 io_uring & epoll 的效能,我寫了一個 play_iouring 專案使用 monoio & tokio 套件測試:
tcp echo server : 同時 10, 100, 1000 個 tcp client
file I/O : 併發讀寫 100 個檔案,每次 64KB
### File I/O (100 files, 64 KiB each)
| Benchmark | monoio | tokio | Δ |
|---------------|------------|------------|----------------|
| Write (100 files) | ~1.32 ms | ~1.95 ms | monoio ~1.5x faster |
| Read (100 files) | ~693 µs | ~1.87 ms | monoio ~2.7x faster |
### TCP Echo
| Benchmark | monoio | tokio | Δ |
|--------------------|------------|------------|----------|
| 10 clients | ~4.12 ms | ~3.98 ms | ~equal |
| 100 clients | ~26.6 ms | ~27.1 ms | ~equal |
| 1000 clients | ~292 ms | ~330 ms | monoio slightly faster |File I/O 有明顯的提升,原因是 tokio 沒用 epoll 管理 File I/O 而是 worker thread + blocking I/O,而 monoio 是用 io_uring 處理 File I/O 可大幅減少 system call,因此 File I/O 不能當作 epoll 跟 io_uring 的比較。
而 TCP Echo 的效能幾乎一樣,io_uring 要有明顯效能提升在於解省大量的 system call,但封包 read write 生命週期中,system call 不是最花時間的,而是 kernel 的 network stack (e.g 封包解析,firewall rule etc),因此 1000 clients 量還不夠到造成顯著的 system call delay,但大量 client 連線在單機測試時,core 不夠下會失準,因此該壓測只證明 epoll 跟 io_uring 在普遍情境下有差不多的性能 。