
The Core of Concurrent Programming: Atomic Operations are Not Locks
An Analysis of CPU MESI and Atomic Mechanisms

Atomic operations are the bedrock of concurrent programming. For instance, a Mutex is often implemented using an atomic Compare-And-Swap (CAS) at its lowest level. While many initially view Atomics as "CPU-level locks," they are actually mechanisms designed to solve memory synchronization issues across multiple CPU cores in a concurrent read/write environment.
The Problem: Why Multi-Core Concurrency Fails
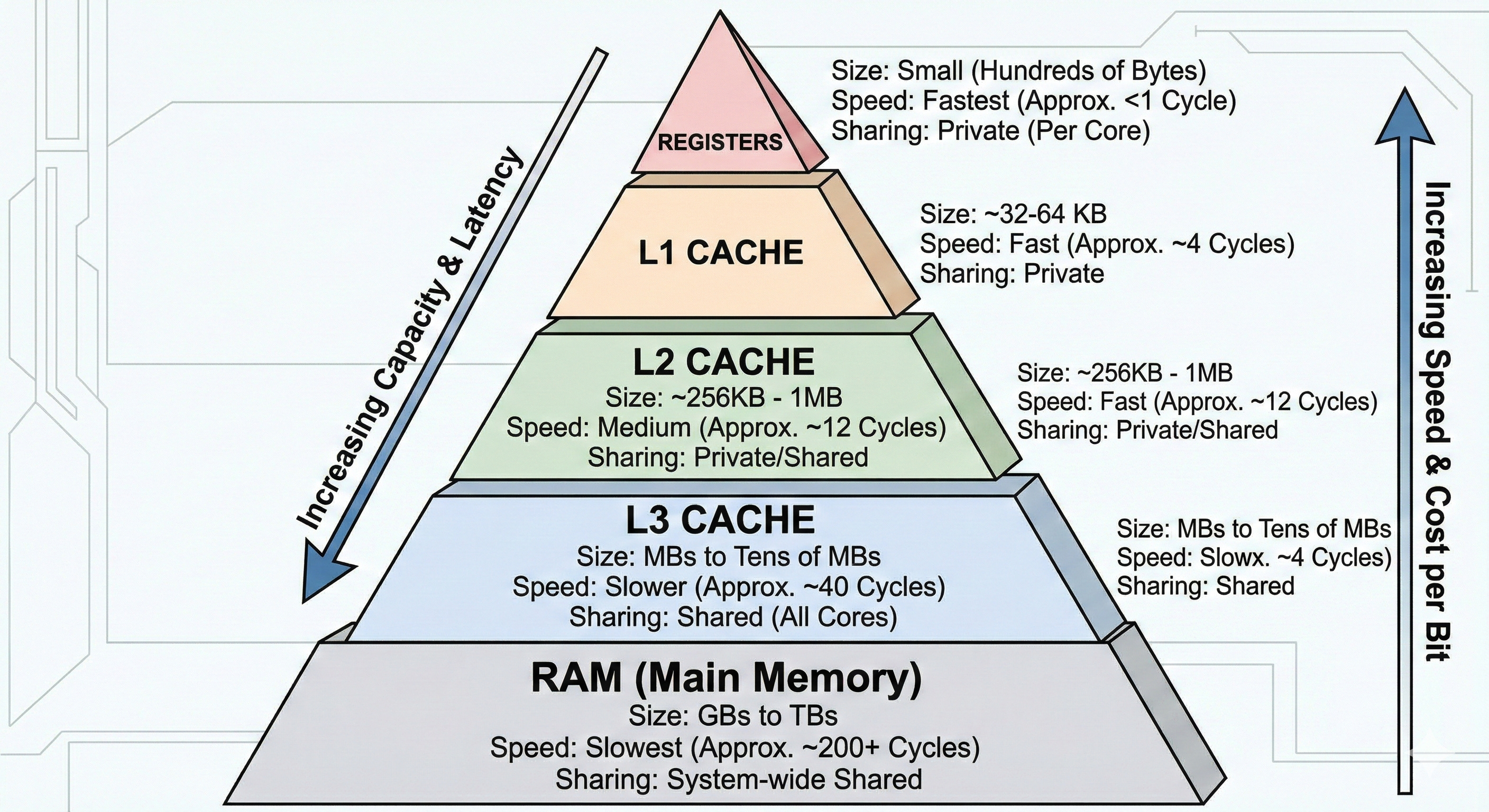
Due to physical limitations in hardware circuitry, larger memory capacity results in higher latency. To mitigate this, CPUs use a Memory Hierarchy to reduce average access costs.
Each core uses Registers to store data during execution. To avoid hitting the RAM for every variable, cores read data in Cache Lines (typically 64B). These are stored in different cache levels:
L1: Private to each core.
L2: Mostly private (architecture dependent).
L3: Shared across all cores.
RAM: The final main memory storage.
When a core looks for data, it checks L1 → L2 → L3 → RAM. Once found, the data is filled back up the chain (L3 → L2 → L1). If a cache is full, it evicts existing lines to make room.
The x++ Race Condition
When multiple cores execute x++, the actual instructions are:
LOAD x → register
ADD 1
STORE register → xIf every STORE had to go straight to RAM, the CPU would be unbearably slow. Instead, modern processors use a per-core store buffer, which temporarily queues writes. These updates are handed off to the cache subsystem, committed into the L1 cache line, and the line is marked dirty. The data is not written back to RAM (or the lower cache levels such as L3) immediately—it is propagated only later, typically when the cache line is evicted or a coherence event forces it.
Because L1 is not shared, two threads on different cores might have their own local copies of the same cache line. They increment their local versions, leading to a Race Condition where updates are lost.
The Solution: Cache Coherency and MESI
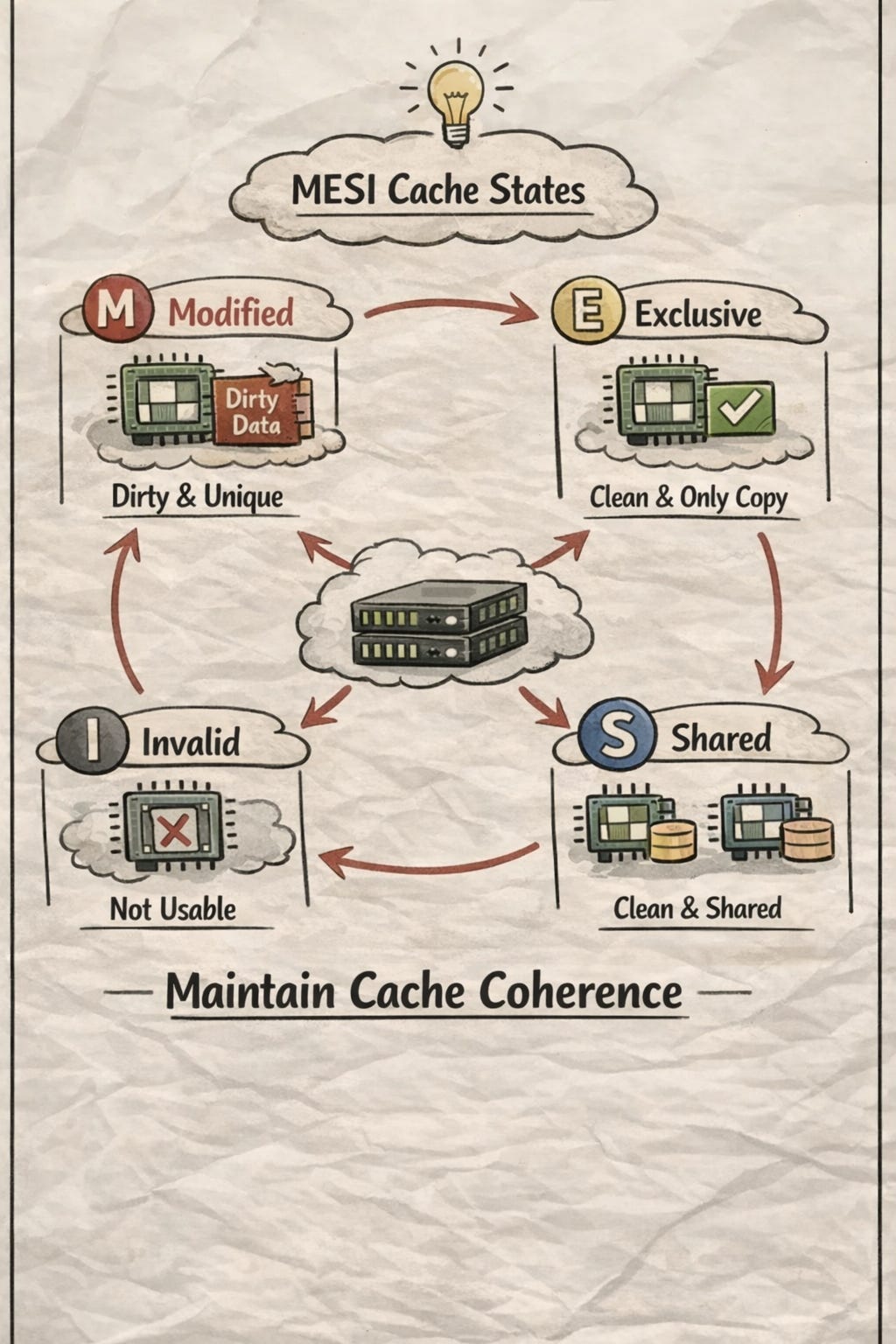
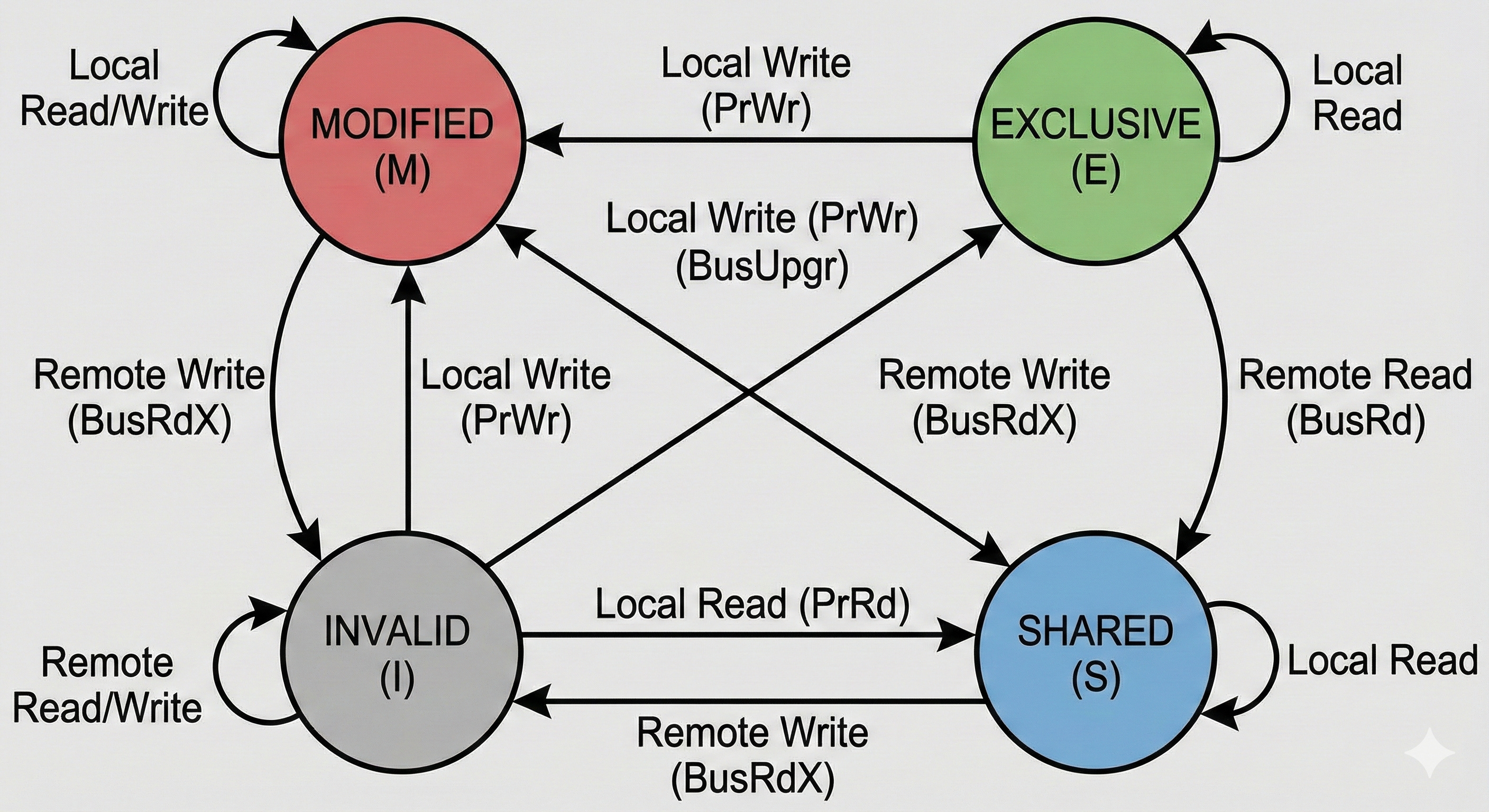
To solve this, hardware designers created a Coherence Interconnect—a high-speed pathway for cores to communicate. Rather than constantly sending data, they exchange Cache Line States to establish Ownership and and trigger write-backs. This is governed by the MESI Protocol:
M (Modified): This core has modified the line; it’s the only copy, and it’s “dirty” (not yet in RAM).
E (Exclusive): This core is the only one with this line; it matches RAM.
S (Shared): Multiple cores have this line; it matches RAM.
I (Invalid): The data is stale because another core modified it.
The MESI State Machine
I → E/S: Core reads the latest state.
S → M: Core gains ownership to write.
M → I: Core receives a notification that another core modified the line.
M → S: Core sees another core wants to read; it immediately syncs to L3/RAM and changes to Shared.
To ensure only one core has ownership at a time, the system uses a BUS (or Ring/Mesh interconnect). Cores Snoop on the BUS for requests and must return an ACK before the BUS processes the next request.
The Role of the BUS in Serialization:
The coherence interconnect (the BUS) acts as a bottleneck by design to enforce order. When multiple cores try to write to the same cache line, the BUS serializes these requests, ensuring they are handled one by one.
For instance, if Core A and Core B simultaneously issue a PrWr (Processor Write) request for cache line X to the BUS:
Through bus arbitration, the system serializes the requests and handles Core A's operation first.
When Core B receives Core A’s
PrWrvia snooping, it transitions its own cache line X state to I (Invalid). Once Core A receives ACKs from all cores, it changes its state to M (Modified).Subsequently, when the BUS processes Core B’s
PrWr, Core B finds its state is already I and cannot transition directly to M. It returns a NACK and switches to a PrRd (Processor Read) request.Once Core A completes its update and receives Core B’s PrRd, it detects that its own state is M, triggers a write-back to L3 or RAM, and changes its state to S (Shared). This allows Core B to read the latest data.
Finally, Core B issues another
PrWrto obtain ownership and executes its update.
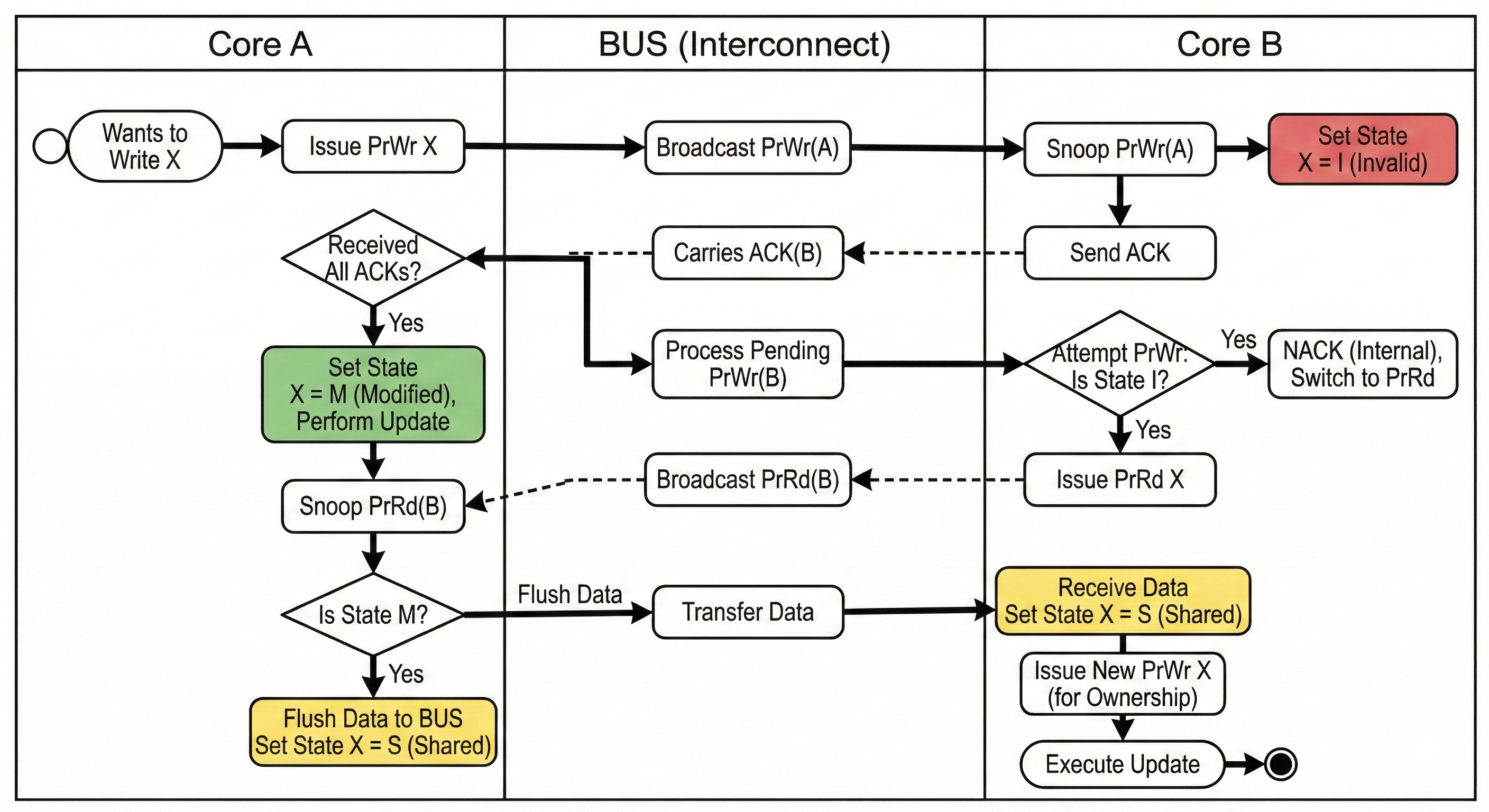
In simple terms, MESI defines the state machine for cache lines, while the centralized BUS serializes the order of state transitions.
Through the snooping and ACK mechanisms, multiple cores ensure that at any given point, cache line states are consistent across the system—preventing two cores from both holding the M state for the same cache line simultaneously.
Why MESI Isn’t Enough: The Need for Atomic Instructions
Even with MESI, the x++ problem persists because x++ is multiple steps.
The x++ operation is composed of three distinct steps:
LOAD x → register
ADD 1
STORE register → xThis process requires two separate state transitions:
1. The LOAD triggers an I → S transition, where the CPU moves x into a register and then performs the ADD.
2. Later, the STORE triggers an S → M transition to write the data back to L1 (and eventually to L3 or RAM when requested).
The problem is that simultaneous LOADs are perfectly legal under the MESI protocol. If Core A and Core B both LOAD x into their registers at the same time, they each hold a local copy of the same value. Even though Core B’s STORE will technically wait for Core A to finish its write (due to BUS arbitration), Core B will still perform the ADD using the stale value already sitting in its register.
In short, the Invalid (I) state transition only affects the cache line; it does not affect data that has already been moved into a register. Once a value is in the register, it is “locked in” for that execution cycle.
How Atomic Solves the Race: LOCK XADD
To resolve this, atomic operations transform x++ into a specialized instruction, such as LOCK XADD. This instruction forces the entire read-modify-write sequence to act as a single, indivisible state transition.
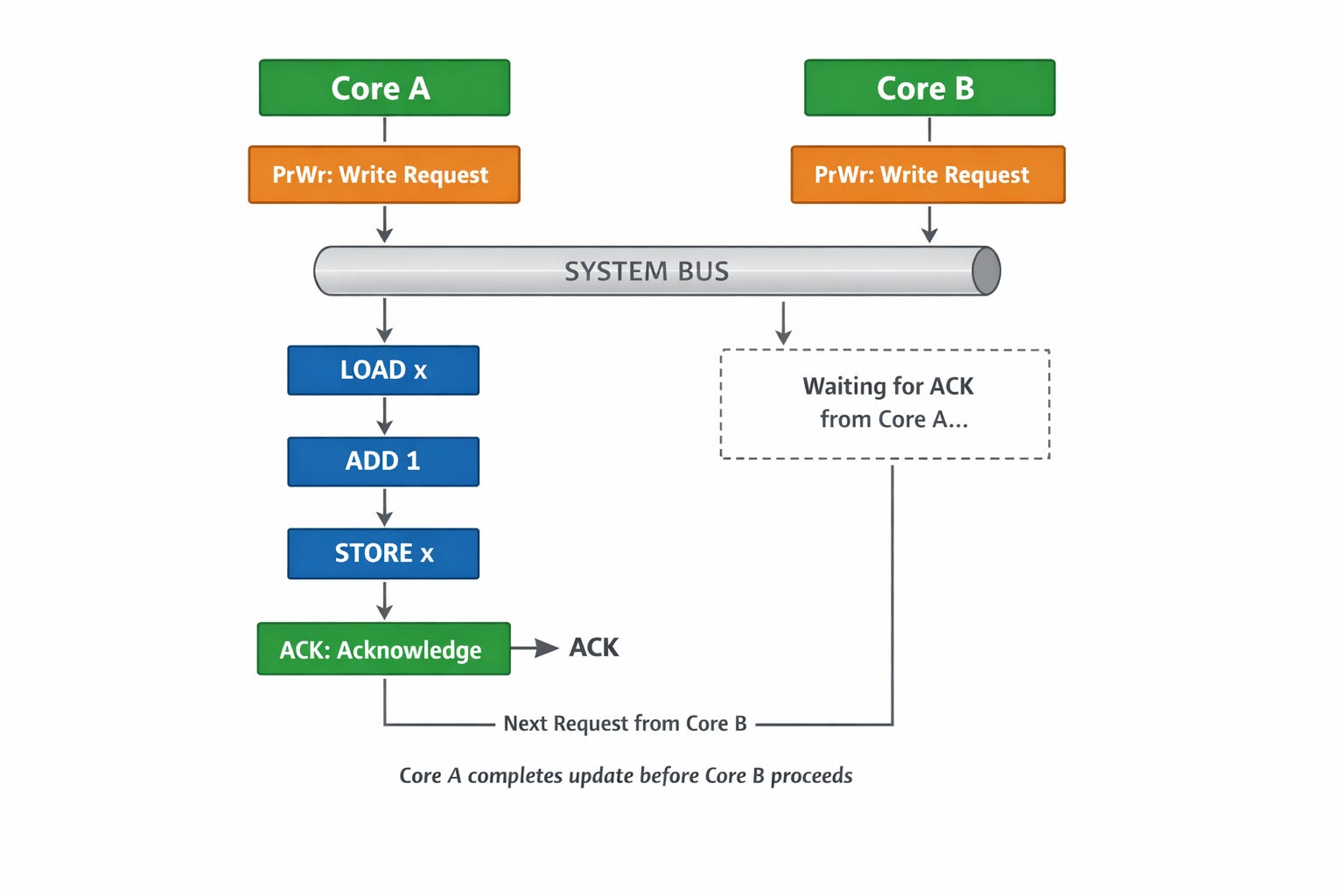
For example, when two cores execute loop { atomic.add(&x, 1) }, they both issue a write request (PrWr) to the BUS:
If the BUS arbitrates and processes Core A first, Core A will execute the entire LOAD → ADD → STORE sequence in one go.
Core A will not return an ACK to any subsequent requests until all three steps are completed.
This ensures that by the time the BUS handles the next request (from Core B), Core A has already synchronized the updated data to the system. This effectively prevents the possibility of Core A and Core B performing a simultaneous LOAD into their registers.
This atomic mechanism is not limited to x++ or x-- it is also the foundation for the CAS (Compare-And-Swap) operation:
// Conceptual CAS Logic
LOAD flag -> register
if flag == 0
flag = 1
STORE register -> flag
STORE true -> ok
else
STORE false -> okCAS is the heart of a Mutex:
// Conceptual Logic
lock => for (!atomic.CAS(&lock, 0, 1)) { /* spin/park */ }
unlock => atomic.CAS(&lock, 1, 0)Optimization Pitfalls: Store Buffers and Invalidation Queues
If Atomics solve the multi-step problem, why do we need atomic.Load and atomic.Store for single-step operations?
The answer lies in Performance Optimizations that cause Memory Reordering.
While MESI ensures cache consistency, the ACK mechanism introduces two significant performance bottlenecks (latencies):
Write Latency: When Core A issues a
PrWr, it must wait for ACKs from all other cores (confirming they’ve invalidated their copies) before it can actually commit the update. During this period, the core is forced to stall.Invalidation Latency: When Core B receives Core A’s
PrWr, it must mark its L1 cache line as Invalid (I) before sending the ACK. Even though cache is fast, it is significantly slower than registers. If the cache is busy, Core A stays stalled even longer.
To optimize performance, CPUs implement Delayed Execution:
The Hardware “Cheats”: Store Buffers & Invalidation Queues
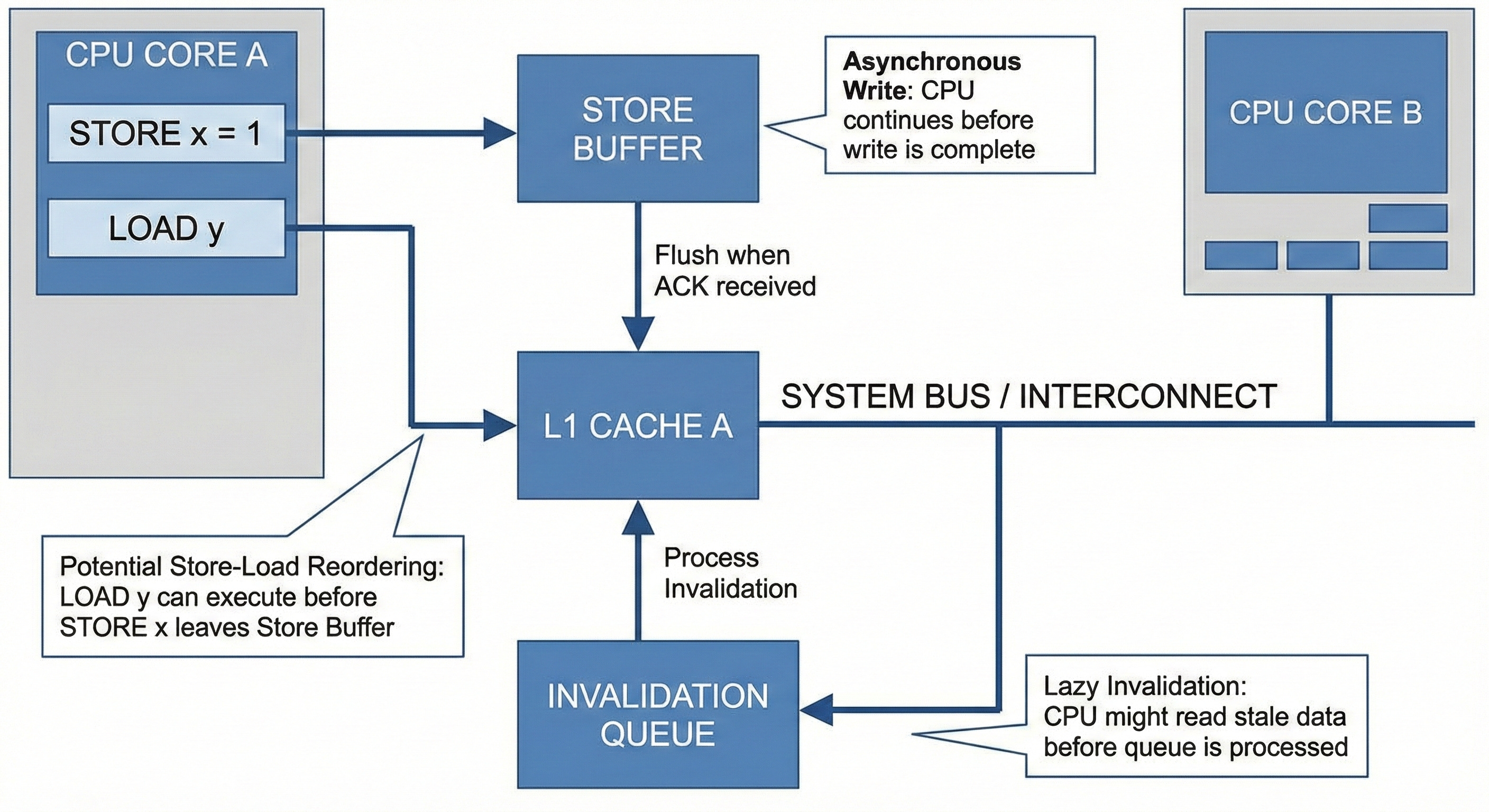
To solve Write Latency: Instead of stalling, the core places the write command into a Store Buffer (a local queue) and moves on to the next instruction immediately.
Example: a = 1; b = y;
STORE 1 => a LOAD y => register STORE register => bFor the
STORE 1 => ais buffered while the core proceeds toLOAD y. Ifyis already in a valid local state (E or S), the core loads it into a register and then executesSTORE register => bbefore the originala = 1even receives its ACKs.To solve Invalidation Latency: When a core receives a
PrWrfrom another core, it doesn’t invalidate its cache line immediately. Instead, it places the request into an Invalidation Queue and sends the ACK instantly to let the sender continue.
The Consequence: Store-Load Reordering
These optimizations cause the order of memory operations to “desync” from the code’s intended sequence. Consider this classic scenario:
x = 0, y = 0, x_res =0, y_res = 0
core A
x = 1
if y == 0 {
x_res = 1
}
core B
y = 1
if x == 0 {
y_res = 1
}In a perfectly sequential world, it is impossible for both x_res and y_res to be 1. At least one write must "happen" before the other core’s check.
However, if both Core A and Core B use Store Buffers, they might both buffer their respective writes (x=1 and y=1) and execute their loads (if y == 0 and if x == 0) before the buffers are flushed. The result? Both cores see 0 for the variables, and both x_res and y_res become 1. This is the Store-Load Reorder problem.
How Atomics Fix Reordering?
atomic.Store and atomic.Load solve this by inserting Memory Barriers (Fences):
1. atomic.Store as a Write Barrier
atomic.Store(&x, 1) essentially tells the CPU: “You cannot execute any subsequent LOAD instructions until the Store Buffer is cleared.” It forces the core to wait until x = 1 receives its ACKs and is committed to the cache.
x = 0, y = 0, x_res =0, y_res = 0
core A
atomic.Store(&x, 1)
// barrier: Before loading y into the register, the store operation on x must be completed first.
if y == 0 {
x_res = 1
}
core B
atomic.Store(&y, 1)
// barrier: Before loading x into the register, the store operation on y must be completed first.
if x == 0 {
y_res = 1
}However, relying solely on atomic.Store does not prevent the following race condition, as invalidation queue optimizations may delay visibility across cores.
Core A executes
atomic.Store(&x, 1). The write barrier forces it to clear its Store Buffer, ensuringx=1is sent out to the coherence interconnect (BUS) via aPrWr(Processor Write) request.Core B receives Core A’s
PrWrforx. However, to optimize performance, Core B does not immediately mark its local cache line as I (Invalid). Instead, it places the invalidation request into its Invalidation Queue and sends back an ACK immediately.Core B then proceeds to its next instruction:
if x == 0.Since Core B has not yet processed its Invalidation Queue, its local cache still thinks
xis valid and contains the value0. Core B reads this stale value, leading toy_res=1.The same sequence happens inversely for Core A reading
y.
Ultimately, even though the write was “sent,” the receiver’s “read” was still stale because the invalidation hadn’t been applied.
2. atomic.Load as a Read Barrier
To prevent this, we must use atomic.Load, which acts as a Read Barrier. Before the LOAD instruction is executed, it forces the core to check its Invalidation Queue.
If the target cache line is pending in the queue, the core must process the invalidation first.
The core then sees the line is Invalid (I) and is forced to fetch the latest value
x=1from the interconnect.
By combining atomic.Store and atomic.Load:
x = 0, y = 0, x_res =0, y_res = 0
core A
atomic.Store(&x, 1)
if atomic.Load(&y) == 0 {
x_res = 1
}
core B
atomic.Store(&y, 1)
if atomic.Load(&x) == 0 {
y_res = 1
}The Store Buffer is flushed on the sender's side, and the Invalidation Queue is prioritized on the receiver's side. This synchronization ensures that x_res and y_res will never both be 1.
Technical Note: While the Invalidation Queue is conceptually a “queue,” the hardware implementation often uses status bits/metadata to check for pending invalidations instantly, rather than performing a linear scan.
Go’s High-Level Encapsulation Compared to Rust’s Fine-Grained Memory Ordering Control
Go’s High-Level Encapsulation
Go’s atomic.Load and atomic.Store provide Sequential Consistency (SeqCst).
atomic.Store: Acts as a Write Barrier, forcing the Store Buffer to clear before moving on.atomic.Load: Acts as a Read Barrier, forcing the core to process its Invalidation Queue to ensure it sees the most recent state.
Rust’s Granular Control
While Go keeps it simple, Rust allows you to specify the Memory Ordering:
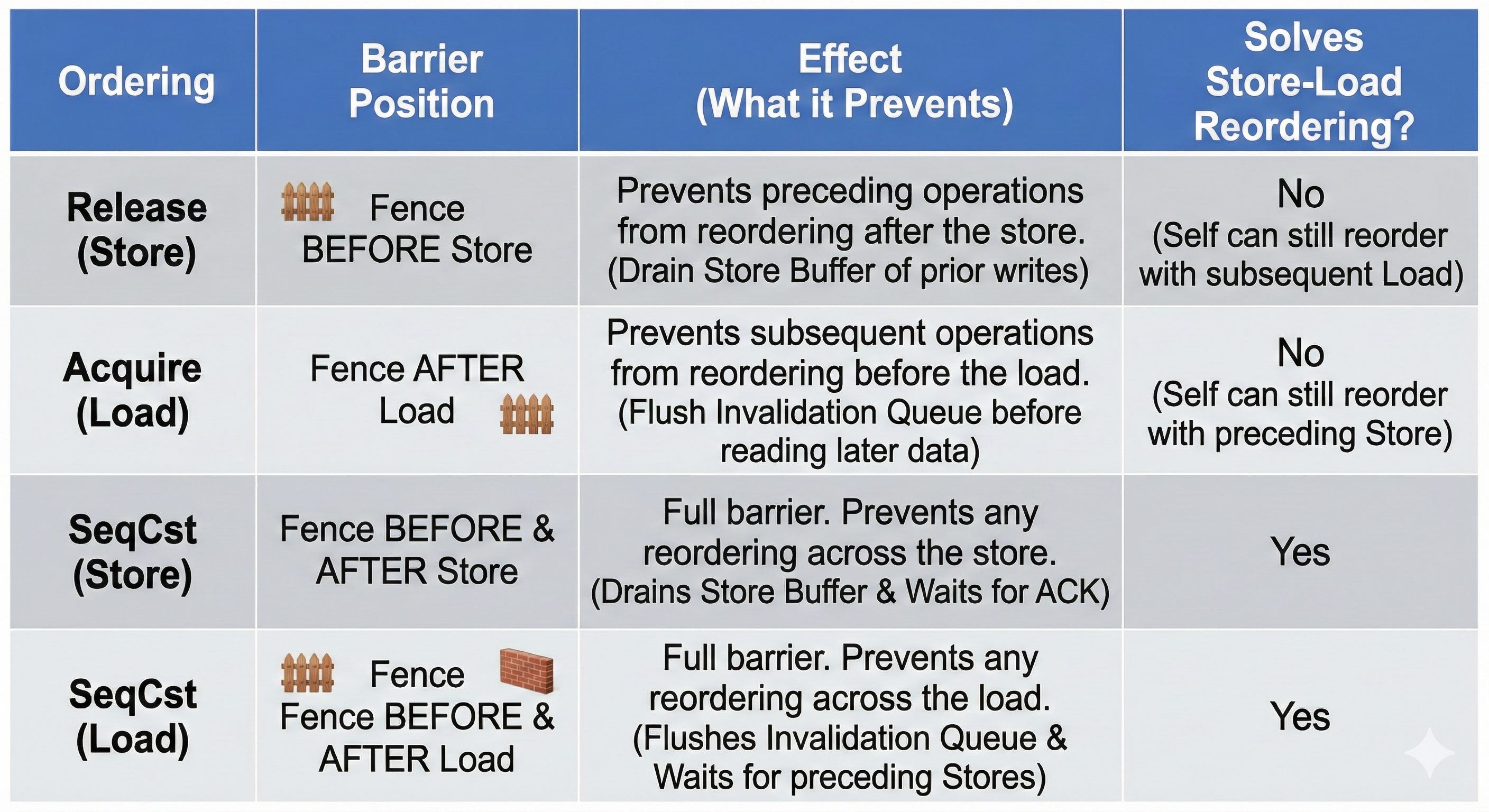
Release/Acquire:
Release (on Store): Ensures all previous writes are visible.
Acquire (on Load): Ensures all subsequent reads see the latest data.
The Release/Acquire pattern in above scenario does not fully prevent the race condition:
x = 0, y = 0, x_res =0, y_res = 0
core A
atomic.Store(&x, 1, Release)
if atomic.Load(&y, Acquire) == 0 {
x_res = 1
}
core B
atomic.Store(&y, 1, Release)
if atomic.Load(&x, Acquire) == 0 {
y_res = 1
}Since the Release barrier precedes the STORE to x, the write may remain in the store buffer and be propagated later, while the LOAD of y can still be issued beforehand.
Proper Use Case for the Release/Acquire Pattern:
Consider the following scenario:
flag = 0, x = 0
core A
x = 1
atomic.Store(&flag, 1, Release)
core B
for atomic.Load(&flag, Acquire) { print(x) } // guarentee to print 1The Release/Acquire pattern is intended for one-way “handover” synchronization.
Core A performs the data write x = 1 and then publishes the update by storing to flag with Release semantics. Core B spins on flag using Acquire semantics; once it observes flag == 1, it is guaranteed to see the preceding write to x.
Release/Acquire is designed for "Handover" (One-way) synchronization, making them faster but trickier to use than SeqCst.
Relaxed:
No barriers at all. It only guarantees that the operation itself is atomic (no torn writes), but provides no guarantees about the order of surrounding instructions.
Example code demonstrating the use of atomic in Go and Rust
Go: Flag Competition & Memory Visibility
The following Go code demonstrates two goroutines competing for a flag. Because we use atomic.Store and atomic.Load (which provide Sequential Consistency in Go), the program remains stable.
func main() {
for i := 0; ; i++ {
x, y, r1, r2 := int64(0), int64(0), int64(0), int64(0)
wg := sync.WaitGroup{}
wg.Add(2)
go func() {
defer wg.Done()
atomic.StoreInt64(&x, 1)
if atomic.LoadInt64(&y) == 0 { // if Store-Load reordering occurs, y will read 0
r1 = 1
}
}()
go func() {
defer wg.Done()
atomic.StoreInt64(&y, 1)
if atomic.LoadInt64(&x) == 0 { // if Store-Load reordering occurs, x will read 0
r2 = 1
}
}()
wg.Wait()
if r1 == 1 && r2 == 1 {
panic(fmt.Sprintf("Observed reordering at iteration %d: r1=%d, r2=%d\n", i, r1, r2))
}
}
}How to Break It:
Remove
atomic.Load: Change the reader to a simpleif flag == 1. Because the Invalidation Queue might not be flushed immediately, the reader might seeflag == 1but still read a stalex == 0from its own cache. It will likely panic after a short run.Remove both Store and Load: Use standard assignments (
flag = 1). The Store Buffer and Caching will cause the program to panic almost instantly, as the cores will be completely out of sync regarding the order of operations.
Rust: Fine-Grained Ordering (Release/Acquire)
While Go simplifies things with a single atomic model, Rust allows us to use Release and Acquire semantics. This is perfect for “Handover” scenarios where one thread produces data and another consumes it.
Rust Example: Ordered Printing (1-1000)
In this example, two threads work in tandem to print numbers. We use Release when writing to the flag to ensure previous memory operations are visible, and Acquire when reading to ensure we see those changes.
use std::sync::Arc;
use std::sync::atomic::{AtomicBool, AtomicUsize, Ordering};
use std::thread;
fn main() {
let n = 1000;
let i = Arc::new(AtomicUsize::new(1));
let flag = Arc::new(AtomicBool::new(true));
let (i_a, flag_a) = (Arc::clone(&i), Arc::clone(&flag));
let t1 = thread::spawn(move || {
loop {
if flag_a.load(Ordering::Acquire) {
let current: usize = i_a.fetch_add(1,Ordering::Relaxed);
if current > n {
flag_a.store(false, Ordering::Release);
break;
}
println!("{}", current);
flag_a.store(false, Ordering::Release);
}
}
});
let (i_b, flag_b) = (Arc::clone(&i), Arc::clone(&flag));
let t2 = thread::spawn(move || {
loop {
if !flag_b.load(Ordering::Acquire) {
let current: usize = i_b.fetch_add(1,Ordering::Relaxed);
if current > n {
flag_b.store(true, Ordering::Release);
break;
}
println!("{}", current);
flag_b.store(true, Ordering::Release);
}
}
});
t1.join().unwrap();
t2.join().unwrap();
}Why this works:
Ordering::Release: On thestore, it acts as a gatekeeper. It ensures that every memory operation before this store (like theprintln!or any data modification) is completed and visible to other cores.Ordering::Acquire: It forces the core to process its Invalidation Queue before the load, ensuring the cache line is fully up-to-date. This allows the core to “see” data synchronized by another core’s Release.Performance: This is more efficient than the default
SeqCst(Sequential Consistency) because it doesn’t require a total global ordering across all cores—only a synchronized “handshake” between these two specific threads.